EMNLP 2017
GCN으로 NMT에 Syntactic info를 인위적으로 주입.
(나한테 영어가 더 편한 단어는 영어로 씀, NMT 관련 논문 요약이 처음이 아니니 traditional NMT model(16시즌의 state-of-the-art) 설명이 많이 생략될 것.)
코드
Abstract
graph-convolutional networks(GCNs)는 graph-structured data를 이용하기 위해 만들어 진 neural net이다. GCNs를 standard encoder(e.g., biRNN, CNN, …)위에 얹음으로써 syntactic structure를 machine translation을 위한 neural attention-based encoder-decoder model에 이용하여 syntax-aware NMT model을 완성하여 machine translation 성능을 높임.
1. Introduction
이제까지 NMT에 syntactic information을 결합시키지 못한 이유로 예상할 수 있는 한가지 이유로, structured information을 neural encoder로 넣어줄 간단하고 효과적인 방법의 부재가 예상된다.
본 논문에서는 graph-convolutional networks (GCNs)(Duvenaud et al., 2015; Defferrard et al., 2016; Kearnes et al., 2016; Kipf and Welling, 2016)를 이용하여 그 문제를 해결하고 syntactic information을 NMT에 결합시킨다. 본 논문에서는 GCN의 한 version인 Syntactic GCNs로 syntactic dependency tree를 이용한다(Syntactic GCNs의 자세한 설명은 아래에서.)
요약하자면, ⁃ introduce a method for incorporating structure into NMT using syntactic GCNs ⁃ show that GCNs can be used along with RNN and CNN encoders ⁃ show that our model is beneficial
2. Background
2.1. Neural Machine Translation
NMT(Kalchbrenner and Blunsom, 2013; Sutskever et al., 2014; Cho et al., 2014b)는 parallel corpus를 이용하여 neural net을 train하고 target sentence given source sentence의 conditional probability를 계산한다.

또한, attention mechanism을 이용하여 decoder가 encoder에 따라 영향을 받으며 작동하게 한다.
2.1.1. Encoders
encoder는 source sentence를 input으로 sequence of hidden states를 만든다.
Recurrent.
걍 RNN, BiRNN 설명임.
RNN은 sequential data를 이용한다.
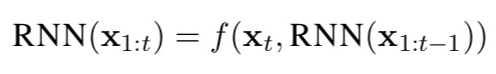
f는 LSTM이나 GRU를 이용함으로 만들어진 비선형함수.
위 식을 이용해서 hidden state들이 계산된다.
이전 words만 사용하지 않고 이후 words도 사용하기 위해 BiRNN이 사용된다.

F: forward, B: backward
Convolutional.
CNN은 fixed-size window를 이용하여 특정 word의 local context를 이용한다.
RNN에 비해 장점이 있다면 fast parallel computation이 가능하다.
Layer를 늘리면 non-local context또한 포함하여 loss를 줄일 수 있다.
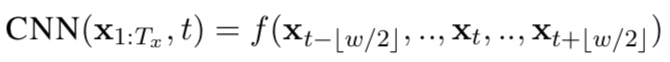
f는 ReLU와 같은 함수가 결합된 비선형함수, w는 window size.
Bag-of-Words.
BoW에는 모든 word를 그의 word embedding으로 encode하고, position 정보를 주기 위해 position embeddings(PE)를 추가할 수 있다. PE를 정의하는 방법에는 여러가지가 있는데, 본 논문에서는 absolute word position을 특정 maximum length까지 학습시킨 vector를 이용함(?)
There are different strategies for defining position embeddings, and in this paper we choose to learn a vector for each absolute word position up to a certain maximum length.
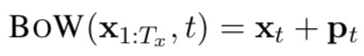
xt는 word embedding, pt는 t-th position embedding.
2.1.2. Decoder
decoder는 encoder가 만든 source sentence의 hidden states를 input으로 target sentence를 만든다. RNN with additional input ci로 만들어져 있는데, 여기서 ci는 context vector. ci는 attention mechanism을 통하여 each time step에 dynamically 계산된다.(Bahdanau et al, 2015)
target word yi의 probability는 decoder RNN state, target word embedding, context vector를 이용하여 계산된다. 그리하여 이 model은 end-to-end maximum log likelihood를 이용하여 next target word given its context를 학습한다(이 부분은 이전 논문 요약글에 자세하게 나옴)
2.2. Graph Convolutional Networks
이제 GCNs(Kipf and Welling, 2016)에 대하여 설명을 할텐데, 더욱 포괄적인 내용을 보려면 (Gilmer et al, 2017) 참고 요망.
GCN은 neighborhood of a nood를 vector로 encoding하여, graph 정보를 직접적으로 이용하는 multilayer neural network. 각각의 GCN layer에서는, 모든 node가 이웃 node의 정보를 받게 되어 있다, information이 graph edge를 따라 흐름. layer가 1개라면 node는 해당 node의 이웃 node의 정보만 받지만 layer가 늘어날수록 가까이 있는 node의 정보를 받는다. GCN layer 수를 조절하여 information travel distance를 regulate할 수 있다.
Undirected graph G=(V, E)가 있다고 하자.
V: set of vertices
E: set of edges
for all v, (v, v)는 E에 포함된다고 가정(모든 점은 자신과 연결됨)
X가 d*n 차원의 행렬로, 모든 node의 정보(dimension d짜리 word embeddings)를 갖고 있다고 하자.
1-layer GCN의 경우, output이 되는 hidden states는 아래와 같다.
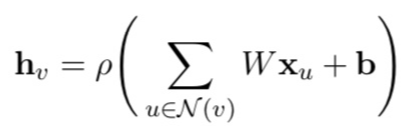
W는 d*d차원의 weight matrix, b는 d차원의 bias vector, 로우는 activation function이다.
요렇게 하면 GCN layer가 더 쌓일 때 recursive computation으로 아래와 같은 식이 나옴.
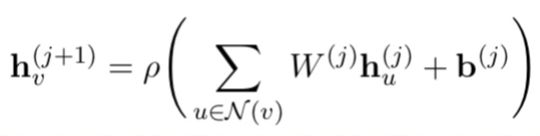
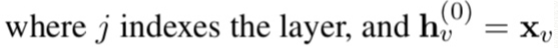
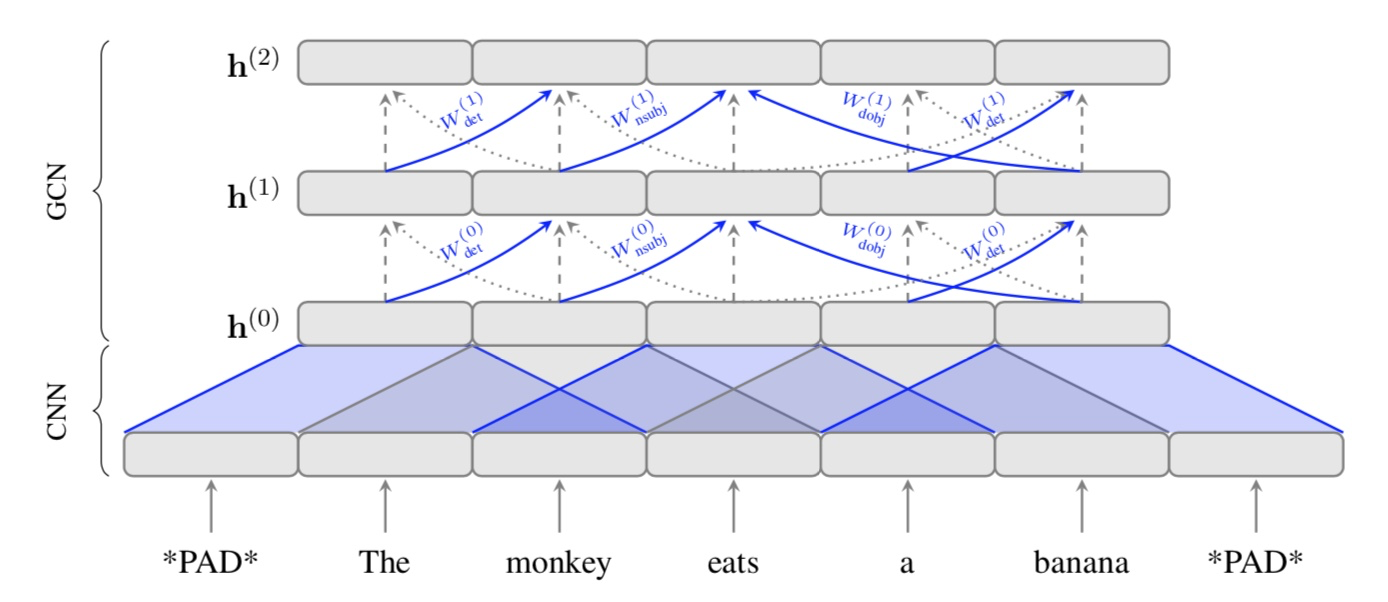
2.3. Syntactic GCNs
Marcheggiani and Titov (2017)는 GCN이 directed, labeled graph에서 작동 가능하도록 발전시켰다. 이것을 이용하면 directionality와 edge label을 가진 linguistic structure(여기서는 dependency tree)를 GCN에 적용시킬 수 있다. 또한, edge-wise gates를 이용하여 model이 각 dependency edge의 기여도를 조절할 수 있다.
Directionality.
directionality를 이용하려면 incoming과 outgoing edge에 다른 weight matrix가 적용되야 한다. dependency tree에서는 edge가 출발점의 dependents로 향하므로, outgoing edge를 head-to-dependent connection, incoming edge를 dependent-to-head connection으로 사용한다. 이제 앞의 general GCN의 recursive computation을 아래처럼 수정할 수 있다.
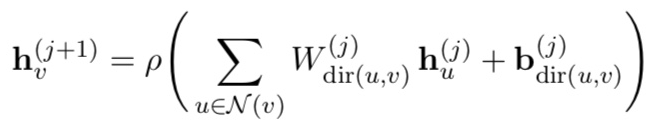
여기서 dir(u, v)는 (u, v)의 방향에 따라 다른 weight matrix를 선택한다.
(Win for u-to-v, Wout for v-to-u, Wloop for v-to-v)
요렇게 하면 이제 weight parameter가 이전의 3배나 있음.
Labels.
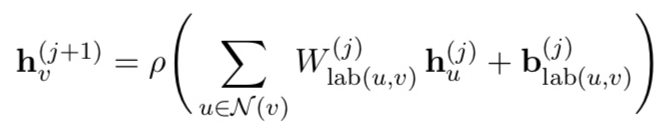
이제 direction에 따라만 W가 바뀌는게 아닌 label과 direction의 combination에 따라 바뀜 => over-parametriztion.
이를 방지하기 위해 W matrix는 direction에 따라서만 바뀌도록 하고 bias term이 label-specific하게 한다.
Edge-wise gating
Syntactic GCNs는 gates가 있어서 각 edge의 기여도를 줄이며 noisy할 경우 noise 조절할 수 있도록 한다. => error가 클 것 같은 edge 무시한다.
그러기 위해 각 edge에서 아래처럼 scalar gate value를 계산한다.
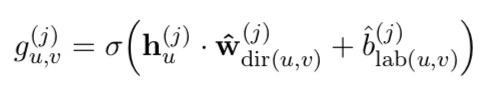
sigma는 logistic sigmoid function.
아래 둘은 gate를 위해 학습된 parameters
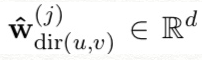
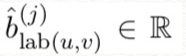
따라서 최종 computation은
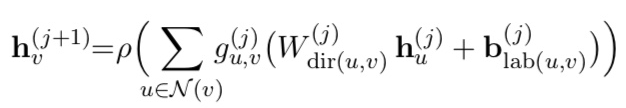
3. Graph Convolutional Encoders
encoder는 기존 encoder structure에 GCN 얹어서 만들고 decoder는 Bahdanau et al. (2015) 따라서 만든다.
모든 곳에서 RNN unit으로는 GRU(Cho et al., 2014b)를 사용한다.
encoder structure는 아래 세가지 모델로 실험하였다.
BoW + GCN.
Convolutional + GCN.
CNN은 Gehring et al. (2016)의 접근을 사용한다. window size는 5.
BiRNN + GCN.
optimiztion을 쉽게 해주기 위해 GCN layer를 2개 이상 사용할 때 residual connection(He et al., 2016)을 만듬.
4. Experiments
Experiments는 Bahdanau et al. (2015)의 모델을 implement한 the Neural Monkey toolkit3 (Helcl and Libovicky ́, 2017)을 사용함. (https://github.com/ufal/neuralmonkey)
Adam optimizer(Kingma and Ba, 2015) 사용함, learning rate은 0.001(CNN은 0.0002)
Batch size는 80.
dropout probability 0.2 in layers and edge dropout in GCNs.(https://github.com/bastings/neuralmonkey <= GCN 코드)
training with 45 epochs.
validation set에서 epoch마다 BLEU score 재고, highest validation BLEU model로 고른다.
L2 regularisation with a value of 10^(-8).
greedy decoder(매 time step마다 highest probability를 가진 output token을 고른다.)
4.1. Reordering artificial sequences
decoder에서 sequence 순서를 다시 맞춰야 함 <= edge를 이용한다.
Data.
vocabulary of 26 types.
random sequences fo 3-10 tokens
각 token은 label을 가지고(5개짜리 label set 중 1개) original predecessor를 가르킨다.
또, 각 token이 5개짜리 ‘fake’ label set 중 1개를 가지고 arbitrary position을 가르키게 한다.
sample 25,000 training & 1,000 validation sequences.
Model.
BiRNN + GCN model 사용.
(a bidirectional GRU with a 1-later GCN on top)
GRU units and GCN layer의 embedding에는 32, 64, 128 units 사용.
Result.
training 6 epochs.
model은 permuted sequence를 다시 order 조정하게 만들도록 학습한다.
validation BLEU가 99.2 달성.
bias terms of gates의 평균 value는 아래와 같은 그래프를 만듬.
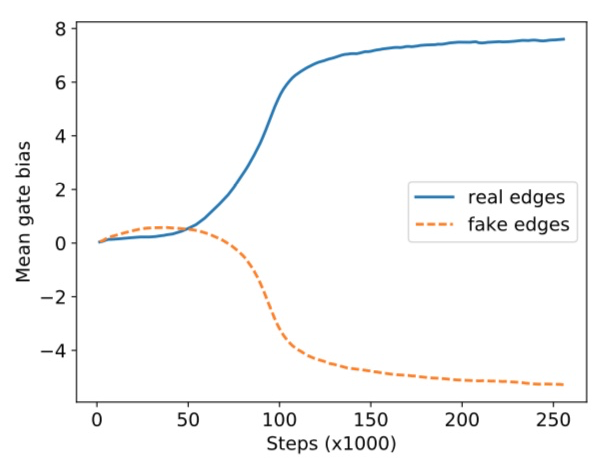
gate가 효과가 좋음을 확인 가능.
4.2. Machine Translation
Data.
실험을 위해 En-De & En-Cs News Commentary v11 data from WMT16 translation task 이용.(http://www.statmt.org/wmt16/translation-task.html)
validation set은 newstest2015, test set은 newstest2016.
Pre-processing.
English side(source side)의 corpora가 SyntaxNet(https://github.com/tensorflow/models/tree/master/syntaxnet)의 pre-trained Parsey McParseface model(The used dependency parses can be reproduced by using the syntaxnet/demo.sh shell script.)을 이용해 dependency tree로 tokenize&parse 된다.
Czech & German side(target side)는 Moses tokenizer(https://github.com/moses-smt/mosesdecoder)를 이용해 tokenize된다.
sentence pair 중 한 쪽이 50 words 이상이면 그 pair는 제외된다.
Vocabularies.
English side에서는 training set에서 4번 이상 등장하는 words 이용.
Czech와 German side에서는 rare words와 합성어에 대처해주기 위해 Sennrich et al. (2016b)의 approach인 byte-pair encoding(BPE) 사용.
(BPE 구조를 몰라서 나중에 해석하겠음.)
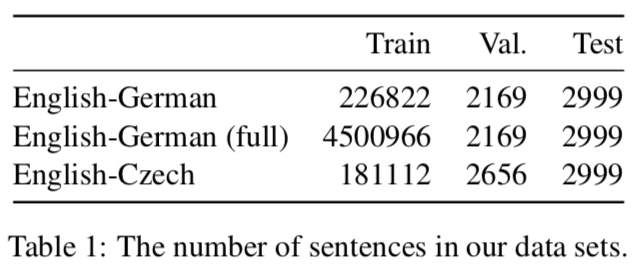
Given the size of our data set, and following Wu et al. (2016), we use 8000 BPE merges to obtain robust frequencies for our subword units (16000 merges for full data experiment). Data set statistics are summarized in Table 1 and vocabulary sizes in Table 2.
Hyperparameters.
256 units for word embeddings.
512 units for GRUs(800 for En-De full data set experiment.)
512 units(channels) for convolutional layers.
GCN layer의 output dimensionality는 input과 똑같게 한다.
GCN layer 2개일 때 가장 effective했음.
Baseline.
baseline은 encoder마다 정해 둠(BoW, CNN, BiRNN 3가지.)
CNN에서 window size w=5
Evaluation.
BLEU result(Papineni et al., 2002) using multi-bleu랑 Kendal 타우 reordering scores.
4.2.1. Results
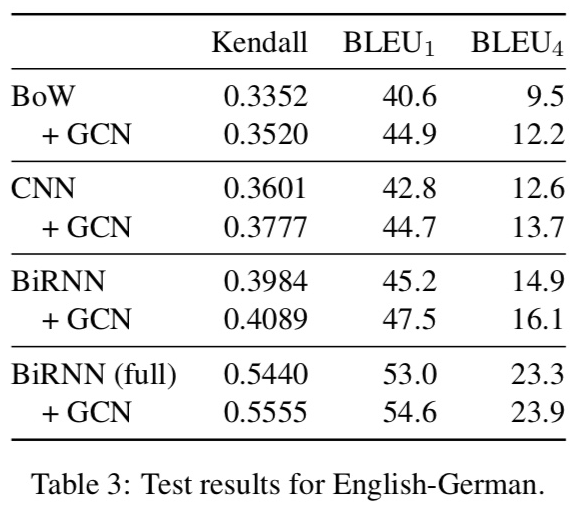
En-Ge
En-Cz
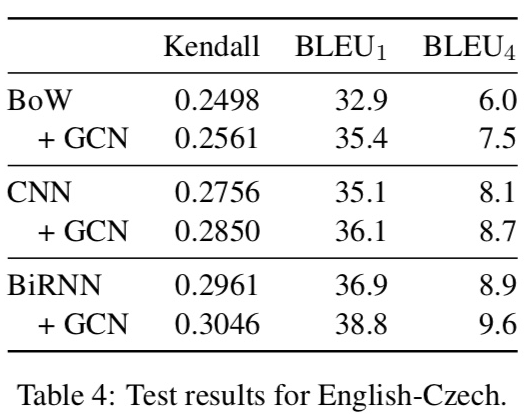
Effect of GCN layers.
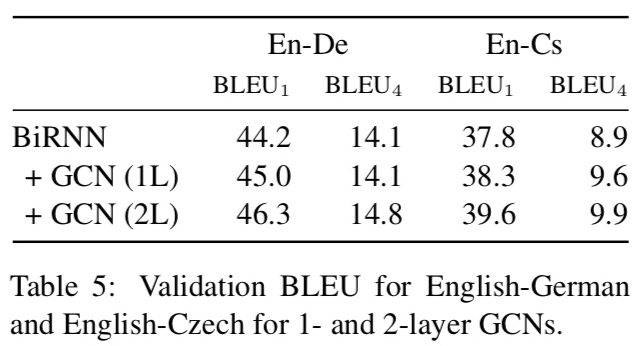
Effect of sentence length.
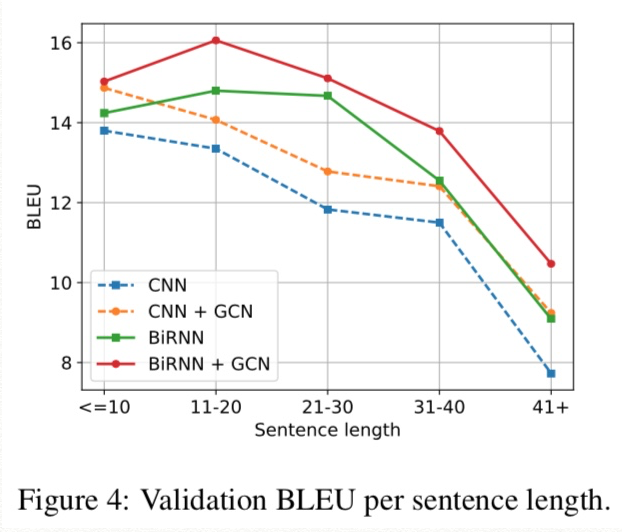
Discussion.
GCN으로 인한 syntax-aware representation이 BLEU4 score의 improvement를 만듬(TER과 BEER도 마찬가지.)
Consistent gains in terms of Kendall tau and BLEU1 indicate that improvements correlate with better word order and lexical/BPE selection, two phenomena that depend crucially on syntax.
5. Related Work
(아래 글은 17년도 당시의 최신 연구 정리하였다. 쭉 읽으면 도움되는데 번역하기는 귀찮음.)
Syntactic features and/or constraints.
Sennrich and Haddow (2016)는 POS-tags, lemmas, dependency labels를 network에 word-embedding과 함께 넣어줌.
Eriguchi et al. (206)은 HPSG parser로 sentence를 parse해 주고 Tree-LSTM으로 tree형식으로 encode해 준다.
Aharoni and Goldberg (2017)는 linearized parse tree로 neural string-to-tree 모델을 제시함.
Multi-task Learning.
Sharing NMT parameters with a syntactic parser is a popular approach to obtaining syntactically-aware representations. Luong et al. (2015a) predict linearized constituency parses as an additional task. (이게 지난 번 요약글=>)Eriguchi et al. (2017) multi-task with a target-side RNNG parser (Dyer et al., 2016) and improve on various language pairs with English on the target side. Nadejde et al. (2017) multi-task with CCG tagging, and also integrate syntax on the target side by predicting a sequence of words interleaved with CCG supertags.
Latent structure.
Hashimoto and Tsuruoka (2017) add a syntax-inspired encoder on top of a BiLSTM layer. They encode source words as a learned average of potential parents emulating a relaxed dependency tree. While their model is trained purely on translation data, they also experiment with pre-training the encoder using tree-bank annotation and report modest improvements on English-Japanese. Yogatama et al. (2016) introduce a model for language understanding and generation that composes words into sentences by inducing unlabeled binary bracketing trees.
Convolutional encoders.
Gehring et al. (2016) show that CNNs can be competitive to BiRNNs when used as encoders. To increase the receptive field of a word’s context they stack multiple CNN layers. Kalchbrenner et al. (2016) use convolution in both the encoder and the decoder; they make use of dilation to increase the receptive field. In contrast to both approaches, we use a GCN informed by dependency structure to increase it. Finally, Cho et al. (2014a) propose a recursive convolutional neural network which builds a tree out of the word leaf nodes, but which ends up compressing the source sentence in a single vector.
6. Conclusion
in future work we would like to go beyond syntax, by using semantic annotations such as SRL and AMR, and co-reference chains.
References(내가 적은 것만)
David K Duvenaud, Dougal Maclaurin, Jorge Iparraguirre, Rafael Bombarell, Timothy Hirzel, Ala ́n Aspuru-Guzik, and Ryan P Adams. 2015. Convolutional networks on graphs for learning molecular fingerprints. In Advances in neural information processing systems, pages 2224–2232.
Michae ̈l Defferrard, Xavier Bresson, and Pierre Vandergheynst. 2016. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain, pages 3837–3845.
Steven Kearnes, Kevin McCloskey, Marc Berndl, Vijay Pande, and Patrick Riley. 2016. Molecular graph convolutions: moving beyond fingerprints. Journal of computer-aided molecular design, 30(8):595–608.
Thomas N. Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks. CoRR, abs/1609.02907.
Nal Kalchbrenner and Phil Blunsom. 2013. Recurrent Continuous Translation Models. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1700–1709, Seattle, Washington, USA.
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to Sequence Learning with Neural Net- works. In Neural Information Processing Systems (NIPS), pages 3104–3112.
KyungHyun Cho, Bart van Merrienboer, Dzmitry Bahdanau, and Yoshua Bengio. 2014a. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. In SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, volume abs/1409.1259, pages 103–111.
Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014b. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1724–1734, Doha, Qatar. Association for Computational Linguistics.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the International Conference on Learning Representations (ICLR).
Diego Marcheggiani and Ivan Titov. 2017. Encoding Sentences with Graph Convolutional Networks for Semantic Role Labeling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark. Association for Computational Linguistics.
Jonas Gehring, Michael Auli, David Grangier, and Yann N. Dauphin. 2016. A convolutional encoder model for neural machine translation. CoRR, abs/1611.02344.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778.
Jindˇrich Helcl and Jindˇrich Libovicky ́. 2017. Neural monkey: An open-source tool for sequence learning. The Prague Bulletin of Mathematical Linguistics, (107):5–17.
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In ICLR.
Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016b. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715– 1725, Berlin, Germany. Association for Computational Linguistics.
Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Lukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, and Jeffrey Dean. 2016. Google’s neural machine translation system: Bridging the gap between human and machine translation. CoRR, abs/1609.08144.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. pages 311–318.
Rico Sennrich and Barry Haddow. 2016. Linguistic Input Features Improve Neural Machine Translation. In Proceedings of the First Conference on Machine Translation (WMT16), volume abs/1606.02892.
Akiko Eriguchi, Kazuma Hashimoto, and Yoshimasa Tsuruoka. 2016. Tree-to-sequence attentional neural machine translation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 823–833, Berlin, Germany. Association for Computational Linguistics.
Roee Aharoni and Yoav Goldberg. 2017. Towards String-to-Tree Neural Machine Translation. ArXiv e-prints.
Minh-Thang Luong, Quoc V. Le, Ilya Sutskever, Oriol Vinyals, and Lukasz Kaiser. 2015a. Multi-task Sequence to Sequence Learning. CoRR, abs/1511.06114.
Akiko Eriguchi, Yoshimasa Tsuruoka, and Kyunghyun Cho. 2017. Learning to Parse and Translate Improves Neural Machine Translation. ArXiv e-prints.
Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros, and Noah A. Smith. 2016. Recurrent neural network grammars. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 199–209, San Diego, California. Association for Computational Linguistics.
Kazuma Hashimoto and Yoshimasa Tsuruoka. 2017. Neural machine translation with source-side latent graph parsing. CoRR, abs/1702.02265.
Dani Yogatama, Phil Blunsom, Chris Dyer, Edward Grefenstette, and Wang Ling. 2016. Learning to compose words into sentences with reinforcement learning. CoRR, abs/1611.09100.
Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aa ̈ron van den Oord, Alex Graves, and Koray Kavukcuoglu. 2016. Neural machine translation in linear time. CoRR, abs/1610.10099.