NIPS 2015
과제라서 했다. Character-level CNN 첫 적용 논문.
15년이 별로 오래된 건 아니라고 생각했는데 확실히 ML이 지금 얼마나 빠르게 연구되는지 알겠더라, 최근 논문을 좀 본 사람들에게는 지루하겠다.
matjax 쓰고 싶은데 너무 복잡하다. 이번 학기 끝나고 부터 써야지.
나한테 영어가 더 편한 표현은 영어로 씀.
읽으면서 15년 논문임을 고려해야 함.
Abstract
text classification에 character-level convolutional networks(ConvNets)를 사용하여 실험을 통한 경험적 결론을 얻는다. (BoW, n-grams, 앞의 둘의 TFIDF variants, word-based ConvNets, RNN과 비교함)
1. Introduction
Text classification은 free-text documents에 predefined category를 부여하는 NLP의 classic topic이다. text classification 연구는 machine learning classifier로 넣어 줄 최적의 feature들을 정하는 것에서 시작되었다. 현재까지(2015) n-gram과 같이 ordered word combination의 종류들이 보통 performance가 가장 좋았고[12], 거의 모든 연구는 text classification을 word 기반 모델로 해결하였다.
반면에, 여러 연구는 convolutional networks (ConvNets)[17][18]을 제시하였고, 이는 computer vision부터 speech recognition and others에 이르기까지 raw signal에서 useful information을 추출하기 위한 좋은 성능을 냈다. 이전에 쓰였던 time-delay networks(TDNN)이 본래 sequential data를 다루는 CNN이라고 할 수 있다.[1][31]
본 논문에서는, text를 raw signal로 받기 위해 character level model을 사용하고, 1-dimensional (temporal) ConvNet을 이용한다. 본 논문에서는 ConvNet이 text data를 다룰 수 있음을 실증하는 classification task만 실험하였다.
Historically we know that ConvNets usually require large-scale datasets to work, therefore we also build several of them. An extensive set of comparisons is offered with traditional models and other deep learning models.
ConvNet을 text classification이나 NLP with large에 사용하는 것은 literature(문학)에 사용되었었는데, [6][16] or [13]을 통해 ConvNet이 directly, extracted syntactic or semantic structures 없이 distributed or discrete embedding of words에 사용될 수 있고, traditional model에 견줄만함을 보았다.
character-level feature를 사용한 related work에는, character-level n-grams with linear classifier[15], character-level feature를 추가로 접목한 ConvNets[28][29]이 있다. 구체적으로, 앞의 ConvNet approach들은 word를 basis로, character-level features extracted at word[28], or word n-gram[29] level form에 사용하였고, POS-tagging이나 information retrieval에서 발전을 보였다.
본 논문이 ConvNet을 only characters에 사용하는 첫번째 시도이다. [6][16][13]이 semantic or syntactic structure가 없어도 학습 가능함을 보인 것에 추가로, large-scale datasets에서 train할 때는 deep ConvNet이 word에 대한 knowledge가 필요없음을 보일 것이다.
이 approach는 language에 따라 달라지는 character constitution에 비해 과도한 simplification일 수 있다. 반면에, only character만을 이용하면 abnormal character combinations such as misspellings and emoticons 문제가 자연스럽게 학습되어 해결될 수 있다.
2. Character-level Convolutional Networks
사용할 structure의 design은 modular. gradient는 back-propagation[27]으로..최적화..당연한 얘기.
2.1. Key Modules
main component는 temporal convolutional module(1-D convolution.)
input function g(x)
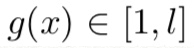
discrete kernel function f(x)
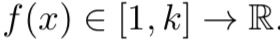
convolution h(y) between f(x) and g(x) with stride d
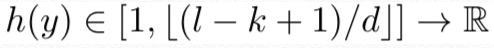
then the whole computation with the layer is like below
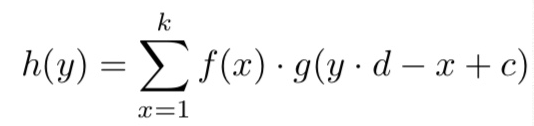
c = k-d+1 is an offset constant.
module은 kernel function fij들로 parameterize된다. <= weights
input과 output도 gi(x), hj(y)로 set을 이룬다.
여기서 gi, hj는 features.
m, n are input and output feature size.
hj(y)는 sum over gi(x)와 fij(x)의 convolution.
복잡해 보일 수 있지만 matrix form으로 CNN 다룰 때 했던 computation 그대로다.
추가로, temporal(1-D) max-pooling 수행함.[2]
discrete input function g(x)
g(x) (오른쪽으로 향한 삼지창) [1, l] => R
max-pooling function h(y)
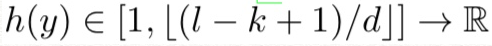
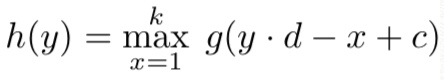
c = k-d+1 is an offset constant.
pooling module은 ConvNet의 layer가 6까지도 깊어질 수 있게 한다.[3]
non-linearity를 위해서 ReLU[24] 사용(\(h(x)=max\left{0,x\right}\)).
stochastic gradient descent(SGD) with minibatch of size 128 using momentum[26][30] 0.9 and initial step size 0.01 which is halved every 3 epochs for 10 times 사용.
Implementation is done by Torch 7[4]
2.2. Character quantization
model의 input으로는 encoding된 character의 sequence가 들어온다.
input language의 size m을 특정함으로 one-hot-encoding할 수 있다.
그러면 input인 sequence of characters는 sequence of m sized vectors with fixed length l0가 된다, l0를 넘는 character는 무시, alphabet에 포함되지 않는 characters는 all-zero vectors.
quantization order는 backward로 하여 마지막으로 읽은 것들이 begin of the output에 가깝게 위치하도록 한다, making it easy for fully connected layers to associate weights with the latest reading.
model의 alphabet은 총 70개의 character로 아래와 같다.
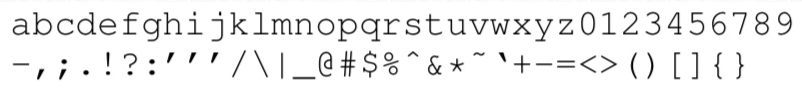
- the new line character
나중에 alphabet도 바꿔서 대소문자를 구분한 모델과 비교함.
2.3. Model Design
large feature와 small feature로 2개의 ConvNet을 구성했고, 모두 6개의 conv layer와 3개의 fully-connected layer가 있다. 3개의 fc 사이에는 정규화를 위해 2개의 dropout이 있고 dropout의 확률은 0.5이다. filter의 stride는 1, pooling은 non-overlapping을 하였으므로 stride는 3.
2 ConvNets 디자인하였다, 1개는 large 1개는 small. 9 layer(6 conv layer + 3 fully-connected layers)
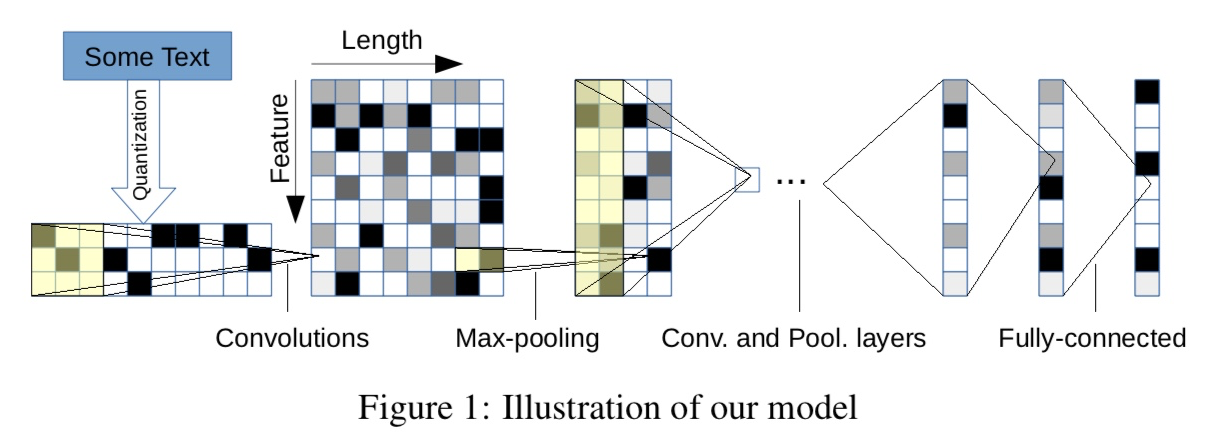
input feature length is 1014.
2 dropout modules[10] in between the 3 fully-connected layers to regularize, with probability of 0.5.
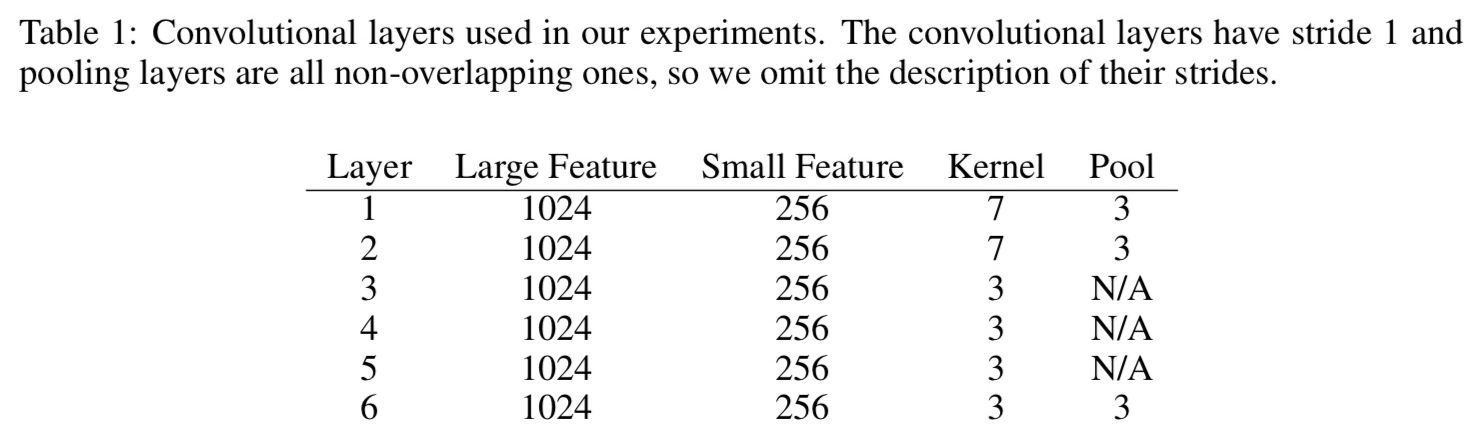
Gaussian distribution에 따라 weight initialization, (mean, std): (0, 0.02) for large, (0, 0.05) for small.

2.4. Data Augmentation using Thesaurus
test augmentation의 가장 좋은 방법은 human rephrases지만 현실적으로 불가능하고, 가능한 가장 자연스러운 방법은 word나 phrase를 synonym으로 대체하는 것이다.
유의어는 온라인 영어사전인 English thesaurus에서 가져왔다. 여기에는 여러 유의어가 많이 쓰이는 순으로 정렬되어 제시되는데, 몇개의 단어를 바꿀것인지 또 몇번째 순위의 유의어로 바꿀것인지는 각각 0.5확률의 geometric distribution를 따르게 하였다.
3. Comparison Models
3.1. Traditional Methods
classifier로는 multinomial logistic regression을 사용.
-
Bag-of-words and its TF-IDF : 상위 빈도 50000개의 단어들을 가지고 출현수를 단어의 feature로한 bag-of-words와 출현수 대신 TF-IDF로 한 모델. 여기서 IDF는 train set의 전체 sample중 해당 단어를 가지고 있는 sample로 계산.
-
Bag-of-ngrams and its TF-IDF : 5-grams 까지 중 가장 frequent한 n-gram 500,000개. TF-IDF는 동일한 과정
-
Bag-of-means on word embedding : train data에 word2vec을 사용한 것에 k-means clustering을 하여, 분류하는것. 5회이상 출현한 모든 단어를 고려하였고 embedding의 dimension은 300이었다. 각 bag-of-means(cluster를 말하는듯)의 평균 feature는 count로 하였는데, 5000이 평균이었다.
3.2. Deep Learning Methods
- word-based CNN : pretrained word representation(word2vec using lookup table)을 사용했고 embedding size는 똑같이 300이다. 비교를 위해 char-CNN과 레이어 수나 output size는 같다.
 

- LSTM : 역시 word-based이고 pretrained word2vec으로 300차원 embedding. 이 모델은 모든 LSTM cell에서 나온 값을 평균내어 feature vector로 삼고, 이를 가지고 multinomial logistic regression을 하였다.
3.3. Choices of Alphabet
알파벳 대/소문자 구분해보았으나 성능이 더 좋지 않았다. 이 경우에 대/소문자에 따라 semantic이 변하지 않아 regularization으로 작용하지 않았나 추측한다.
4. Large-scale Datasets and Results
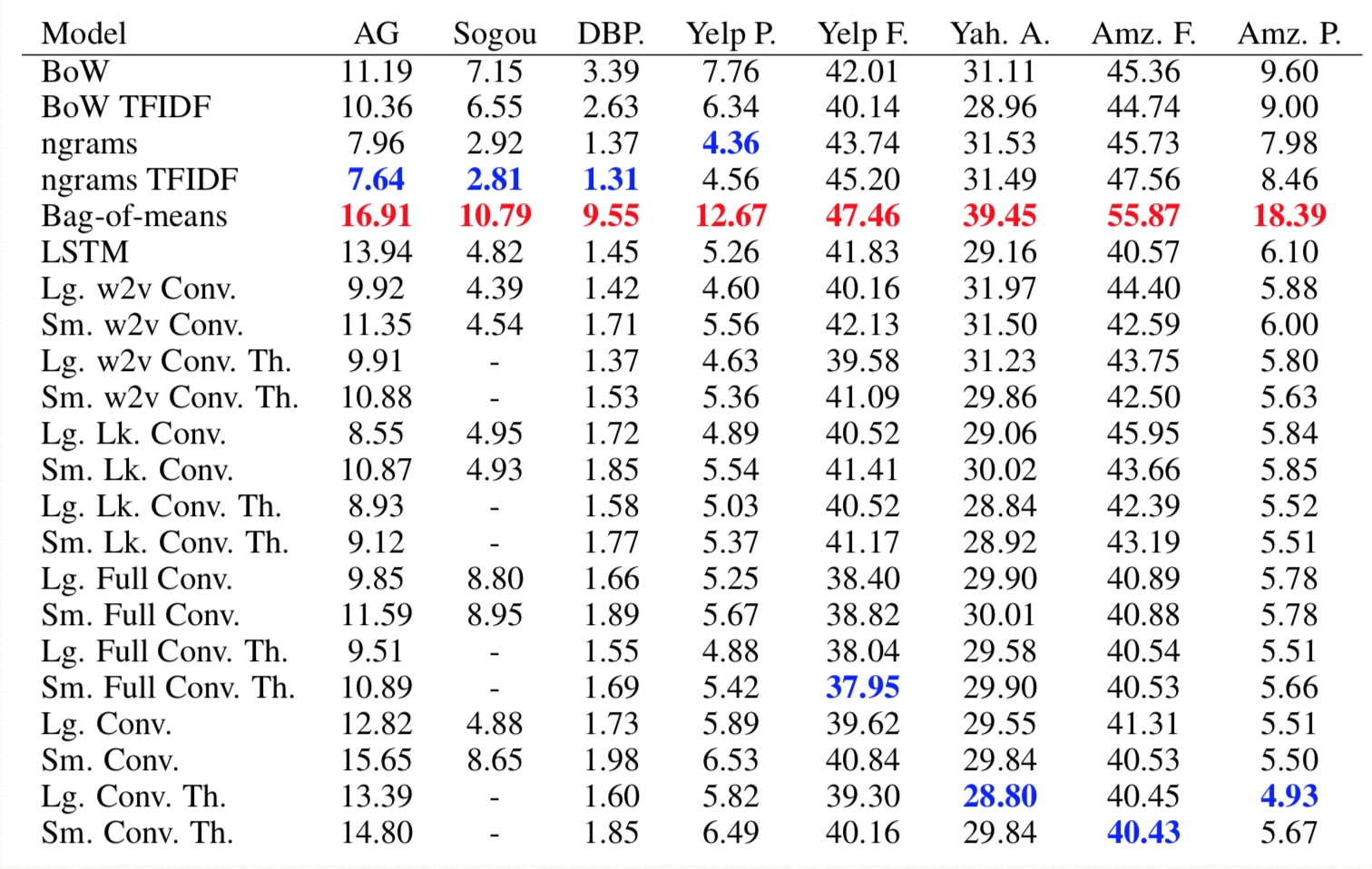
아래 table과 같이 dataset을 모음.
실험 결과는 다음과 같음, 결과로 나온 값은 testing error(빨강은 worst, 파랑은 best)
5. Discussion
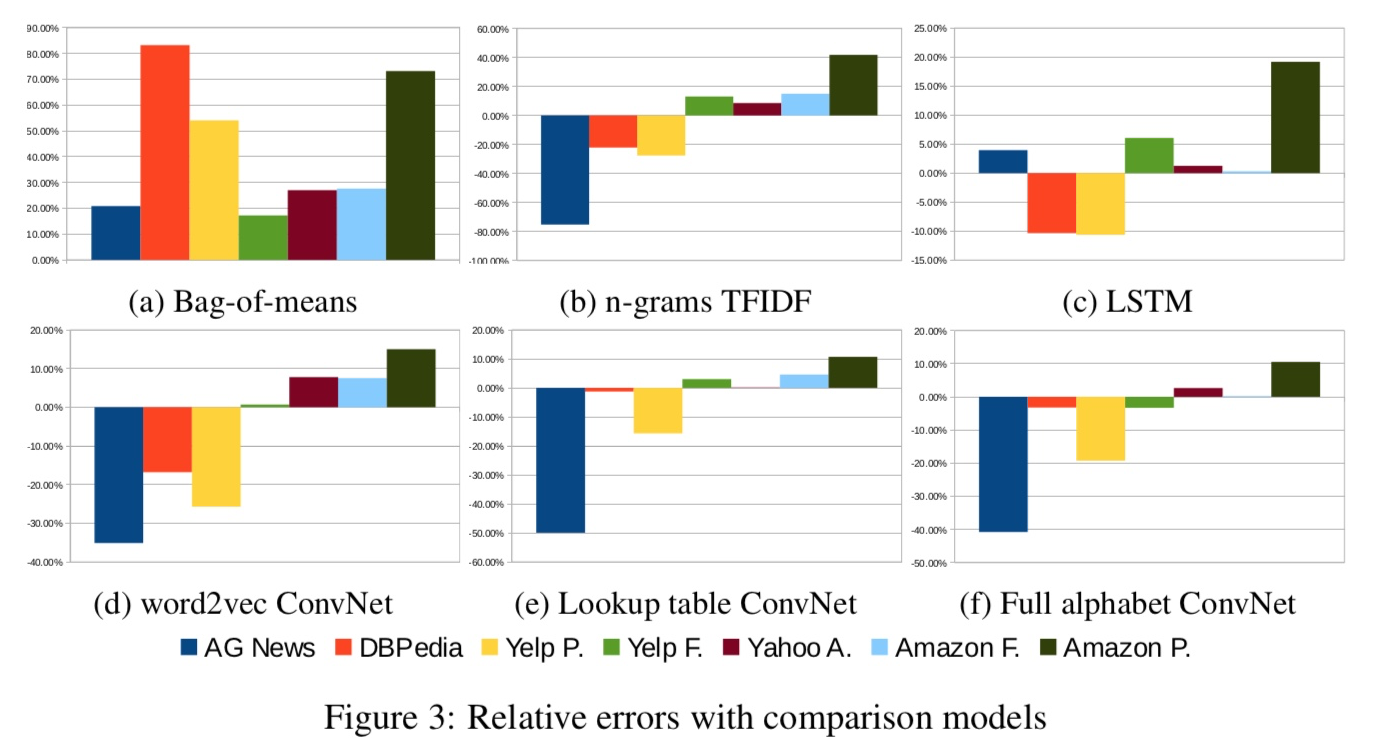 
위 그래프는 각 method별, 각 주제별 Char-CNN과의 오류율 차이%로 나타낸것. (양의 방향으로 막대가 긴 게 Char-CNN이 잘한것)

위 그래프는 각 method별, 각 주제별 Char-CNN과의 오류율 차이%로 나타낸것. (양의 방향으로 막대가 긴 게 Char-CNN이 잘한것)
- Character-level ConvNet is an effective method: word를 찾을 필요 없다는 점에서, 언어 데이터를 다른 데이터와 같은 방식으로 다룰 수 있다는 강점이 있다.
- Dataset size에 따라 데이터 사이즈가 작을때에는 n-gram TFIDF가 여전히 잘했다. 그러나 데이터 scale이 많아질수록 char-CNN이 잘했다.
- ConvNets may work well for user-generated data : Amazon같이 curated 되지 않은 user-generated text (신경쓰지 않은, 막 쓴, 정도의 의미)에서 char-CNN이 더 잘 작동하였다. 이는 현실문제에 더 작용될 가능성을 의미하지만, 논문에서 추가적인 실험은 하지 않았기에 확신하지 못함.
- 알파벳 대/소를 구분한것이 데이터 양이 많을수록 더 잘 못했는데, 아마 regularzation effect가 아닌가 ‘추측’한다.
- semantic 분류를 할것인지(아마존과 yelp), 주제 분류를 할것인지(다른 데이터들)의 차이에 따른 성능은 크게 차이가 없었다.
- Bag-of-means is a misuse of word2vec : word2vec을 단순 분포로 삼아 classification을 하는것은 잘못된 활용인 것 같다. 결과가 좋지 않았다.
- There is no free lunch : 모든 경우에 뛰어난 방법은 없었다. 우리 결과를 보고 적용에 참고해라.
6. Conclusion and Outlook
여러가지 condition에서 실험, character-level convolutional network를 이용한 text classification task에서의 효율을 실험적으로 얻어냈다.
In the future, we hope to apply character-level ConvNets for a broader range of language processing tasks especially when structured outputs are needed.
References
[1] L. Bottou, F. Fogelman Soulie ́, P. Blanchet, and J. Lienard. Experiments with time delay networks and dynamic time warping for speaker independent isolated digit recognition. In Proceedings of EuroSpeech 89, volume 2, pages 537–540, Paris, France, 1989.
[2] Y.-L.Boureau, F.Bach, Y.LeCun, and J.Ponce. Learning mid-level features for recognition. In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, pages 2559–2566. IEEE, 2010.
[3] Y.-L. Boureau, J. Ponce, and Y. LeCun. A theoretical analysis of feature pooling in visual recognition. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), pages 111–118, 2010.
[4] R. Collobert, K. Kavukcuoglu, and C. Farabet. Torch7: A matlab-like environment for machine learning. In BigLearn, NIPS Workshop, number EPFL-CONF-192376, 2011.
[5] R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and P. Kuksa. Natural language processing (almost) from scratch. J. Mach. Learn. Res., 12:2493–2537, Nov. 2011.
[6] C. dos Santos and M. Gatti. Deep convolutional neural networks for sentiment analysis of short texts. In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, pages 69–78, Dublin, Ireland, August 2014. Dublin City University and Association for Computational Linguistics.
[7] C. Fellbaum. Wordnet and wordnets. In K. Brown, editor, Encyclopedia of Language and Linguistics, pages 665–670, Oxford, 2005. Elsevier.
[8] A.Graves and J.Schmidhuber. Framewise phoneme classification with bidirectional lstm and other neural network architectures. Neural Networks, 18(5):602–610, 2005.
[9] K. Greff, R. K. Srivastava, J. Koutn ́ık, B. R. Steunebrink, and J. Schmidhuber. LSTM: A search space odyssey. CoRR, abs/1503.04069, 2015.
[10] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012.
[11] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Comput., 9(8):1735–1780, Nov. 1997.
[12] T. Joachims. Text categorization with suport vector machines: Learning with many relevant features. In Proceedings of the 10th European Conference on Machine Learning, pages 137–142. Springer-Verlag, 1998.
[13] R. Johnson and T. Zhang. Effective use of word order for text categorization with convolutional neural networks. CoRR, abs/1412.1058, 2014.
[14] K. S. Jones. A statistical interpretation of term specificity and its application in retrieval. Journal of Documentation, 28(1):11–21, 1972.
[15] I. Kanaris, K. Kanaris, I. Houvardas, and E. Stamatatos. Words versus character n-grams for anti-spam filtering. International Journal on Artificial Intelligence Tools, 16(06):1047–1067, 2007.
[16] Y. Kim. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1746–1751, Doha, Qatar, October 2014. Association for Computational Linguistics.
[17] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Back-propagation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, Winter 1989.
[18] Y.LeCun, L.Bottou, Y.Bengio, and P.Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, November 1998.
[19] J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P. N. Mendes, S. Hellmann, M. Morsey, P. van Kleef, S. Auer, and C. Bizer. DBpedia - a large-scale, multilingual knowledge base extracted from wikipedia. Semantic Web Journal, 2014.
[20] G. Lev, B. Klein, and L. Wolf. In defense of word embedding for generic text representation. In C. Bie- mann, S. Handschuh, A. Freitas, F. Meziane, and E. Mtais, editors, Natural Language Processing and Information Systems, volume 9103 of Lecture Notes in Computer Science, pages 35–50. Springer Inter- national Publishing, 2015.
[21] D. D. Lewis, Y. Yang, T. G. Rose, and F. Li. Rcv1: A new benchmark collection for text categorization research. The Journal of Machine Learning Research, 5:361–397, 2004.
[22] J. McAuley and J. Leskovec. Hidden factors and hidden topics: Understanding rating dimensions with review text. In Proceedings of the 7th ACM Conference on Recommender Systems, RecSys ’13, pages 165–172, New York, NY, USA, 2013. ACM.
[23] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Wein- berger, editors, Advances in Neural Information Processing Systems 26, pages 3111–3119. 2013.
[24] V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), pages 807–814, 2010.
[25] R. Pascanu, T. Mikolov, and Y. Bengio. On the difficulty of training recurrent neural networks. In ICML 2013, volume 28 of JMLR Proceedings, pages 1310–1318. JMLR.org, 2013.
[26] B. Polyak. Some methods of speeding up the convergence of iteration methods. {USSR} Computational Mathematics and Mathematical Physics, 4(5):1 – 17, 1964.
[27] D.Rumelhart, G.Hintont, and R.Williams. Learning representations by back-propagating errors. Nature, 323(6088):533–536, 1986.
[28] C. D. Santos and B. Zadrozny. Learning character-level representations for part-of-speech tagging. In Proceedings of the 31st International Conference on Machine Learning (ICML-14), pages 1818–1826, 2014.
[29] Y. Shen, X. He, J. Gao, L. Deng, and G. Mesnil. A latent semantic model with convolutional-pooling structure for information retrieval. In Proceedings of the 23rd ACM International Conference on Confer- ence on Information and Knowledge Management, pages 101–110. ACM, 2014.
[30] I.Sutskever, J.Martens, G.E.Dahl, and G.E.Hinton. On the importance of initialization and momentum in deep learning. In S. Dasgupta and D. Mcallester, editors, Proceedings of the 30th International Conference on Machine Learning (ICML-13), volume 28, pages 1139–1147. JMLR Workshop and Conference Proceedings, May 2013.
[31] A. Waibel, T. Hanazawa, G. Hinton, K. Shikano, and K. J. Lang. Phoneme recognition using time-delay neural networks. Acoustics, Speech and Signal Processing, IEEE Transactions on, 37(3):328–339, 1989.
[32] C. Wang, M. Zhang, S. Ma, and L. Ru. Automatic online news issue construction in web environment. In Proceedings of the 17th International Conference on World Wide Web, WWW ’08, pages 457–466, New York, NY, USA, 2008. ACM.