ACL 2017
RNNG를 이용해 NMT의 학습에 target sentence의 syntactic info 주입.
(나한테 영어가 더 편한 단어는 영어로 씀)
코드: https://github.com/tempra28/nmtrnng
Abstract
원래 Neural Net을 도입한 기계번역은 linguistic prior 정보를 인위적으로 결합시키지 않은 방향이 효율이 좋았다. 최근 들어(아마 2016년이겠지?) linguistic prior(syntactic info)를 결합시키는 시도가 몇가지 나왔다. 그 연구들 대부분 source side의 linguistic prior를 고려하는데, 이 논문에서는 output side의 syntactic info를 이용한다. NMT(Neural Machine Translation)에 Recurrent Neural Net Grammar(Dyer et al., 2016) 구조를 결합한 NMT+RNNG라는 모델을 이용하여, parse & translate을 학습하도록한다.
1. Introduction
이런~저런~시도들이 있었는데, 여기서는 external parser를 이용하여 target parse action을 추가한 뒤 training한다. 이렇게 하면 test time에는 이 과정이 필요 없음. experiment에서는 NMT+RNNG 모델로 4개의 언어 pair ({JP, Cs, De, Ru}-En)을 가지고 실험하였고, BLEU score와 RIBES score에서 improvement를 얻었다.
2. Neural Machine Translation
최신 NMT는 encoder와 decoder로 작용하는, attention model을 내재한 2개의 RNN으로 이루어짐. encoder는 LSTM이나 GRU를 이용한 bidirectional RNN. 먼저 source sentence를 sequence of words x=(x1, x2, …, xN) 구조로 읽고, encoder가 sequence of hidden states h=(h1, h2, …, hN) 구조로 반환한다. 각 hidden state hi 는 forward 와 backward RNN의 concatenation이므로 hi=[forward hi, backward hi]로 표현된다.
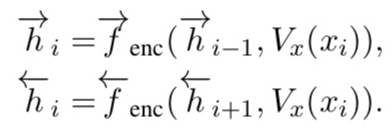
Vx(xi)는 i-th source word의 word vector를 나타내고 decoder는 target sentence를 conditional recurrent language model로 표현해준다.
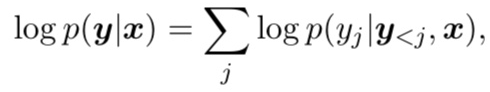
여기서 y = (y1, …, yM), output으로 들어갈 수 있는 word들.
conditional probability들은 아래와 같이 계산된다.
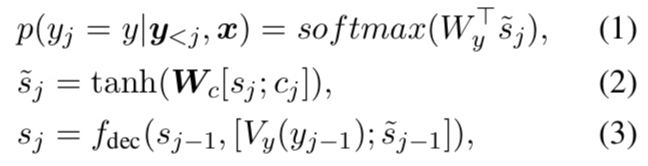
Wy는 word y의 output word vector.
fdec는 LSTM/GRU에서 사용하는 recurrent activation function
cj는 encoder의 hidden state sequence h를 이용하여 attention model이 계산한 time-dependent context vector.
cj를 계산하는 과정은, 먼제 attention model이 current hidden state sj를 각 hidden states와 비교하여 scalar score beta i,j를 부여한다.
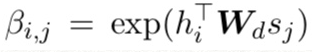
그리고 normalize
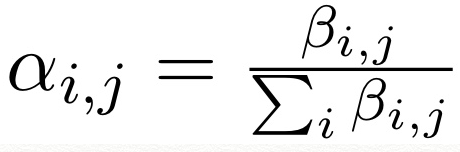
그리고 time-dependent context vector는 위를 이용한 weighted sum으로 계산됨
3. Recurrent Neural Network Grammars
RNNG는 probabilistic syntax-based language model.
RNN과 달리 RNNG는 token과 tree-based composition을 모두 동시에 model에 때려박음.
이렇게 하려면 (output) buffer와 stack, action history가 필요함, 이것들은 stack LSTM(sLSTM)(Dyer et al., 2015)을 사용하여 implement된다. each time, action sLSTM이 current hidden states of the buffer stack and action sLSTM을 기반으로 다음 action을 예측한다.
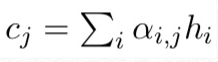
여기서 Wa는 action a의 vector.
action이 shift라면 buffer의 첫번째 word가 stack으로 감.
action이 reduce라면 top-two words in the stack이 partial tree를 만드는데 사용됨.
추가로 action은 non-terminal symbol이 될수도 있으며 그러면 해당 symbol이 stack으로 push됨.
hidden states of the buffer, stack, action sLSTM은 아래와 같이 update된다.
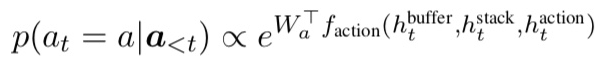
여기서 Vy와 Va는 target word와 action vector를 return하는 함수.
stack sLSTM의 input vector rt는 아래와 같이 계산된다.

여기서 r^d와 r^p는 parent와 dependent phrases의 corresponding vectors.
이 과정은 recursively, parse tree가 완성될 때까지 돌아간다. RNNG의 original paper는 constituency tree를 사용하지만 여기서는 dependency tree를 사용한다.
complete sentence가 제공되면 buffer가 shifted words를 요약하고, RNNG가 generator 역할을 할 때 selected action이 shift일 경우 next word를 generate해준다. (buffer => recurrent language model) 마지막 부분 잘 이해안간다. 선행 논문이 있으니 설명을 대충한건가, 천천히 더 봐야겠음, 아마 아래쪽에서 이해될 듯.
4. Learning to Parse and Translate
4.1 NMT+RNNG
본 논문의 목표를 이루려면, RNNG의 buffer를 recurrent language model로 바꿔야함(shifted words를 요약, future words를 generate해 주는). 이 과정은 two step을 거친다.
Construction
아래 식 두개를 보면, buffer sLSTM과 translation decoder 모두 각각의 이전 hidden state을 input으로 가진다.
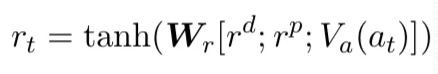
이전의, buffer의 hidden state를 나타낸 표현식 (5)을 아래의 hidden state of the decoder of the attention-based neural machine translation으로 바꾼다.
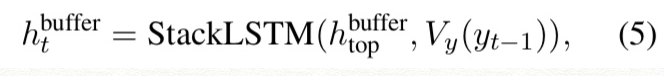
둘의 차이점은 translation decoder는 추가로 state ~sj-1을 고려한단 것인데, 위의 replacement를 수행한 뒤에는 NMT decoder도 RNNG의 action의 control안에 있게 되는데, j-th hidden state in Eq(3)이 shift action이 예측된 겅우에만 계산되므로 본 모델이 sequence of words and action with different length를 다 handle할 수 있다.
다음으로, next word prediction of translation decoder를 RNNG의 generator가 해주게 한다.
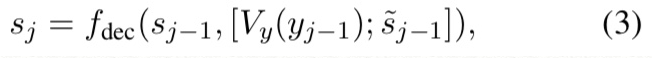
이 식(conditional distribution defined in translation decoder)에 따라 shift action이 예측되었을 때 output word를 만들어 준다.
이젠 buffer sLSTM이 neural translation decoder로 대체됨. action sLSTM이 decoder의 hidden state를 input으로 가지고 action conditional distribution(Eq (4))을 계산하고, 이 모델이 바로 NMT+RNNG
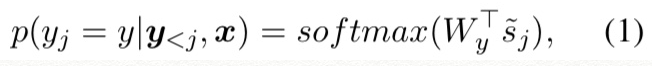
Learning and Inference
이제 NMT+RNNG model은 가능한 모든 translation과 parse(앞에서 만든 parse tree인 듯) pair의 conditional distribution을 계산해준다. 그 확률은 아래와 같음.
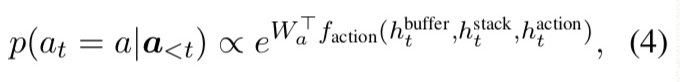
이렇게 하면 NMT+RNNG model은 아래의 식을 object function으로 갖음.
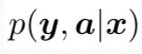
y뿐만 아니라 a의 conditional probability도 maximize한다. 이 효과로, 전체 translation model이 target language의 syntactic structure를 준수하는 방향으로 train되고, 결과적으로 train이 끝난 뒤 inference time에 RNNG의 stack과 action sLSTM을 제거해도 효과는 지속된다.
4.2 Knowledge Distillation for Parsing
소개한 hybrid model을 이용하는데 문제점이 있다. 바로 본 모델의 training을 위한 target-side sentence와 pair를 이룬 gold-standard target-side parse 자료가 없다는 점이다. parallel corpus 구해서 target-side sentences에 annotate해줘도 되지만, 여기서는 존재하는 parser를 이용하여 noisy corpus를 만들어 준다. 이것이 바로 Knowledge Distillation. SyntaxNet(Andor et al., 2016)을 사용한다. 그 후 parse tree를 sequence of actions(SHIFT, REDUCE-L, REDUCE-R)로 변환하여 사용한다. 여기서 REDUCE action은 해당하는 dependency label로 label해준다.
5. Experiments
5.1 Language Pairs and Corpora
NMT+RNNG 모델을 이용해 Jp-En, Cs-En, De-En, Ru-En 네가지 쌍의 translation 해줌.
End of Sentence에는 “EOS”, low-frequency words에는 “UNK” 붙여줌
Jp
WAT’16 Jp-En translation task의 ASPEC corpus (“train1.txt”)를 사용하고, KyTea(Neubig et al., 2011)를 이용하여 tokenize함. training할 때는 corpus에서 길이가 50보다 작은 앞의 100K개의 sentence pair를 사용하고, vocabulary는 training corpus에서 두 번 이상 등장하는 단어들로 이루어짐. WAT’16의 data에서 “dev.txt”와 “test.txt”를 사용.
Cs, De and Ru
News Commentary v8을 이용함. noisy metacharacter는 remove하고 Moses(Koehn et al., 2007)의 tokenizer를 사용하고 6번 이상 등장하는 token들로 각 언어의 vocabulary를 만든다, target-side인 En vocabulary에는 3번 이상 등장하는 token들로 이루어 짐. sentence pair 중 source나 target에 empty line을 포함하는 pair는 버리고(이런 게 있나봄) 길이가 50 이하인 sentence pair를 training으로 사용, “newstest2015”는 devset으로, “newstest2016”은 testset으로 사용한다.
5.2 Models, Learning and Inference
RNN은 a single layer of LSTM units of 256 dimensions를 가짐.
word vector는 256, action vector는 128 dimensions. computational overhead를 줄이기 위해 BlackOut(Ji et al., 2015)(with 2000 negative samples and alpha=0.4)을 사용.
BlackOut을 사용할 때, we shared the negative samples of each target word in a sentence in training time(?)(Hashimoto and Tsuruoka, 2017) for proposed NMT+RNNG, we share the target word vectors between the decoder(buffer) and the stack sLSTM.
모든 initial weight은 [-0.1, 0.1]에서 uniform distribution을 따라 배정된다. bias vectors, weights of the softmax and BlackOut은 초기에 zero로 설정된다. LSTM과 sLSTM의 forget gate bias는 초기에 1로 설정된다. 128 사이즈의 minibatch를 이용한 stochastic gradient descent를 사용. learning rate는 1.0로 시작하여 devset의 perplexity increase(의도치 않은 결과, 아마 cost가 늘어날 때를 의미하는 듯)마다 반으로 준다.
We clip the norm of the gradient(Pascanu et al., 2012) with the threshold set to 3.0 (2.0 for the baseline models on Ru-En and Cs-En to avoid NaN and Inf). <=모름
앞에서 말한 perplexity increase 시에, learning rate를 반으로 줄이면서 해당 epoch 직전의 model을 reload한다.
RNNG의 stack이 dependency parse tree의 vector를 compute하는데, parse tree가 가지는 “ROOT” node는 “EOS”로 한다. inference time에는 beam search를 사용하고 beam width는 devset performance를 기반으로 선택된다.
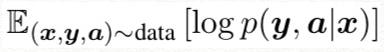
score 결과. statistical significance를 계산하기 위해서 bootstrap resampling method(Koehn, 2004) 사용, 십자가 마크는 significance cases with p<0.005
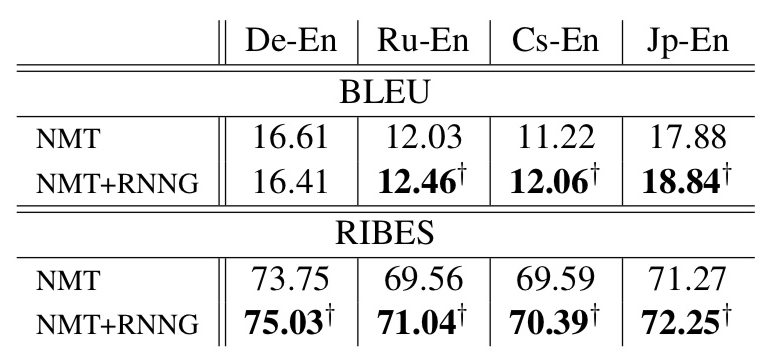
Jp-En test에서 RNNG 구성 요소 조절한 실험 결과.
5.3 Results and Analysis
NMT+RNNG model 성과, 성공적.
Ablation
Jp-En test에서 처럼 RNNG 모델의 구성요소 빼봤는데, 다 있을 때가 제일 좋음.
Generated Sentences with Parsed Actions
기본 NMT decoder가 만드는 translated sentence와 RNNG decoder의 parsing action으로 위 그림과 같은 dependency structure가 만들어 진다. translated sentence는 beam search를 이용하고, parsing actions는 greedy search를 이용한다. resulted dependency structure는 보통 맞지만, 위 그림의 “The”와 “transition”이 “pobj”가 아니어야 하는 것처럼 틀린 경우들도 있다.
6. Conclusion
We propose a hybrid model, to which we refer as NMT+RNNG, that combines the decoder of an attention-based neural translation model with the RNNG. This model learns to parse and translate simultaneously, and training it encourages both the encoder and decoder to better incorporate linguistic priors. Our experiments confirmed its effectiveness on four language pairs ({JP, Cs, De, Ru}-En). The RNNG can in principle be trained with-out ground-truth parses, and this would eliminate the need of external parsers completely. We leave the investigation into this possibility for future research.
References(내가 적은 것만)
Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros, and A. Noah Smith. 2016. Recurrent neural network grammars. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. pages 199–209.
Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, and A. Noah Smith. 2015. Transition-based dependency parsing with stack long short-term memory. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. pages 334–343.
Daniel Andor, Chris Alberti, David Weiss, Aliaksei Severyn, Alessandro Presta, Kuzman Ganchev, Slav Petrov, and Michael Collins. 2016. Globally normalized transition-based neural networks. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. pages 2442– 2452.
Shihao Ji, S. V. N. Vishwanathan, Nadathur Satish, Michael J. Anderson, and Pradeep Dubey. 2015. Blackout: Speeding up recurrent neural network language models with very large vocabularies. Proceedings of International Conference on Learning Representations 2015.
Graham Neubig, Yosuke Nakata, and Shinsuke Mori. 2011. Pointwise prediction for robust, adaptable japanese morphological analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. pages 529–533.
Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, Chris Dyer, Ondrej Bojar, Alexandra Constantin, and Evan Herbst. 2007. Moses: Open source toolkit for statistical machine translation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions. pages 177–180.
Kazuma Hashimoto and Yoshimasa Tsuruoka. 2017. Neural Machine Translation with Source-Side Latent Graph Parsing. arXiv preprint arXiv:1702.02265 .
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. 2012. Understanding the exploding gradient problem. arXiv preprint arXiv:1211.5063 abs/1211.5063.
Philipp Koehn. 2004. Statistical significance tests for machine translation evaluation. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing. pages 388–395.