NAACL 2016
Word -> Sentence -> Document 순서로 계층에 따른 Attention Network
Introduction
기계번역에서 많이 쓰이던 Attention Mechanism을 생각해 봅시다. 우리는 실제 인간이 문장을 읽고 이해하는 방식을 따라서 단어별로 문장의 의미 부여에 기여하는 정도를 Attention State로 만들어 이용했습니다.
본 논문에서 사용하는 모델인 HAN(Hierarchical Attention Networks)은 단순히 말하자면 이전의 Attention Mechanism에서 Word->Sentence로 이루어졌던 구조를 Word->Sentence->Document로 늘린 것입니다.
Hierarchical Attention Networks (HAN)
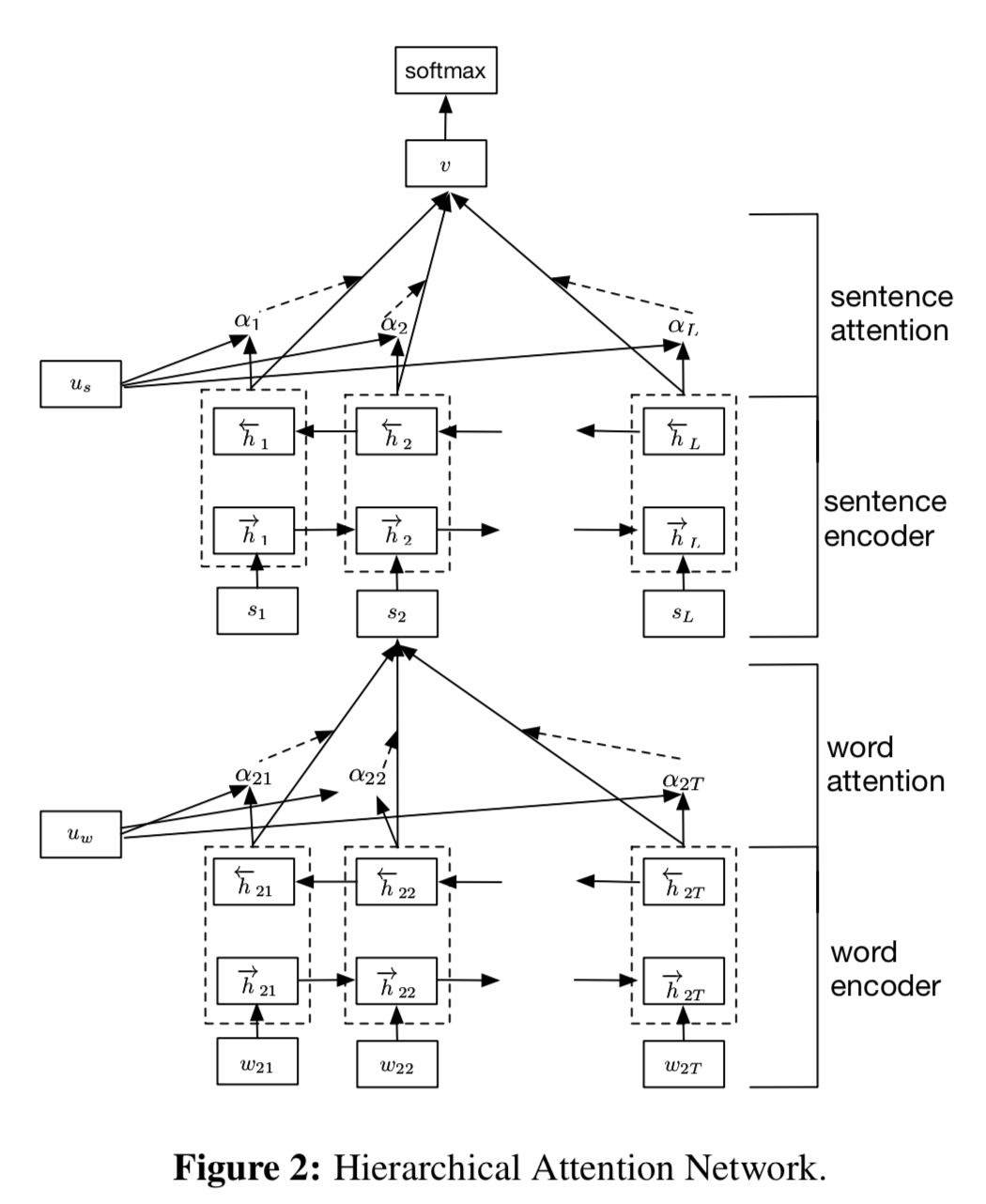
- Word Embedding으로 Word2Vec를 사용합니다.
- RNN 구조로는 Bidirectional GRU를 사용합니다.
- GRU를 통과한 각 단어 Vector에 Attention Layer의 단어별 가중치를 적용하여 합한 값이 Sentence Vector가 됩니다.
- Word->Sentence에서 진행된 과정을 Word2Vec 대신 앞에서 구한 Sentence Vector를 이용하여 반복합니다.
- 구한 Document Vector에 Softmax를 적용하여 확률을 구합니다.
Result