이 글은 제 개인적인 경험과 생각이 많이 담겨 있습니다.
일 년를 돌아보며
서른이 되며 인생을 다시 설계해 보겠다는 포부를 안고 퇴사한 지 어느덧 1년이 지났다. 한가롭게 대전에서 졸업 학기를 보내던 시기도 있었지만, 기다렸다는 듯 개인적인 일들이 큰 장벽처럼 밀려와 정신없이 시간이 흘러갔다. 대치동식 사교육부터 개발자 병특까지 정해진 흐름에 올라탄 느낌이 있었기에 “그때 과학고 준비반에 들어가지 않았다면 지금쯤 어떤 삶을 살고 있었을까?”라는 물음은 이번 갭이어의 중심에 있었고, 지금까지의 시간에 대한 일종의 보상 심리도 함께 작용했다. 혼자 보내는 시간이 많았던 만큼, 몇 가지 부업도 시도해 보고 취미로만 즐기던 일을 본격적으로 공부해 보기도 했다. 그렇게 가능성을 탐색하다 보니, 여러 가지 이유로 결국 ‘개발자’라는 직업이 나에게 가장 잘 맞는다는 확신이 들었다. 한번 스스로를 되돌아보는 시간을 가졌으니 다시 일하고 싶었다. 팀에 몰입하고 그 안에 생기는 불규칙을 그전보다 나은 모습으로 대하고 싶었다.
다시 시작한다면 어떤 개발자가 되어야 할까. 휴식기를 갖기 전, 나는 데브옵스와 데이터 엔지니어를 거치며 플랫폼 중심의 경험을 쌓아왔다. 그 과정에서 줄곧 ML 도메인에서 직접적으로 기여하고 싶다는 마음은 있었다. 다만 커리어 후반부에 맡았던 MLOps 업무에서 생기는 비효율에 대한 어려움과 의문들을 꽤 가졌고, 이제 다시 구직을 한다면, 데이터 플랫폼을 다루는 포지션, 혹은 End-to-End로 AI프로덕트에 기여할 수 있는 포지션을 고려했다. 후자를 택한다면, 최신 모델 구조와 평가 기법 등에 대한 이해를 논문 단위에서 다시 쌓아야 하기에, 기반 지식을 정리할 필요가 있다. 개인 사정상 해외에 거주 중이라 앞으로도 한동안 취업이 어려우니 괜찮은 선택인 것 같았다.
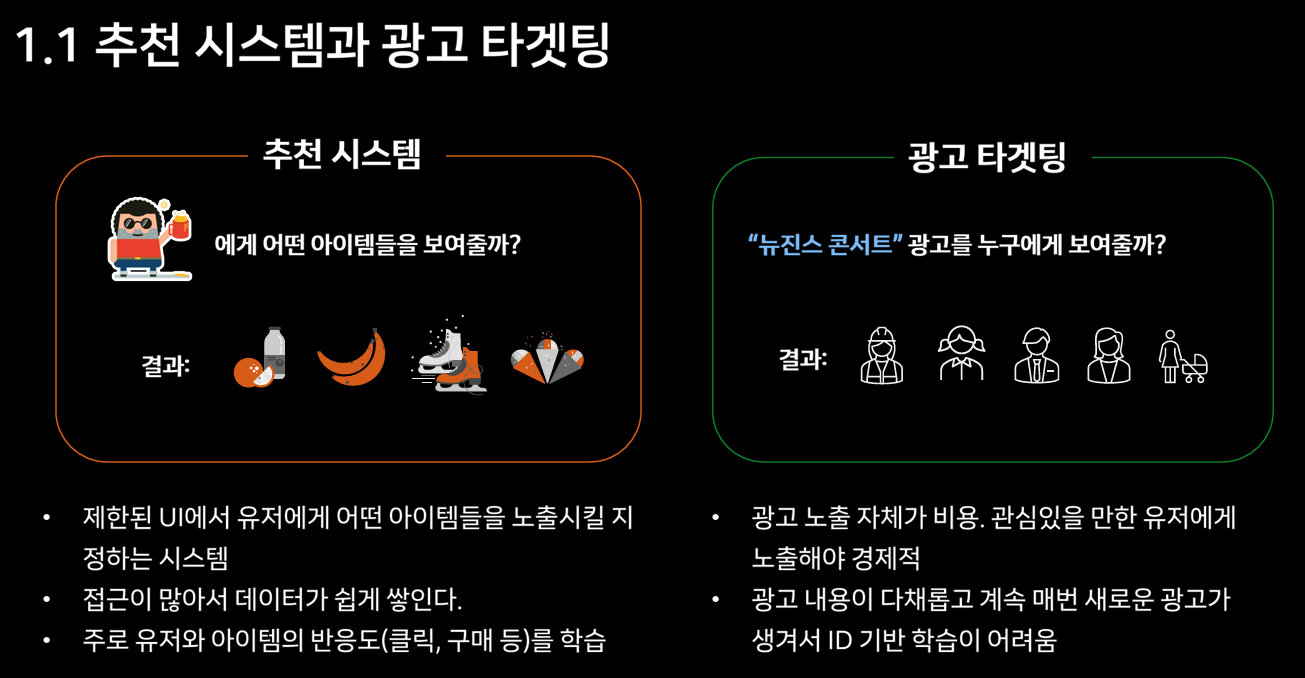
이 과정에서 외부 스터디에서 만나 좋은 인상을 받았던 분과, 평소 눈 여겨봤던 커리어패스를 가진 분에게 조언을 구한 적이 있다. 대체로 파운데이션 모델이 나온뒤로 중소형 회사 중심으로 풀스택으로 AI프로덕트에 기여하는 포지션 수요가 증가하고 있다는 이야기를 들었다. 개인적인 경험으로도, 나는 학습 플랫폼과 배치 파이프라인을 운영하면서 데이터 과학자들의 실험 반복에 무리가 없도록 지원하는 역할을 맡은 적이 있다. 그런데 내가 있던 기간 동안 임팩트를 만들어내는 데이터 과학자 분들은 그런 문제를 겪기보다는, 이미 학습된 모델이나 이를 감싸는 오픈소스를 어떻게 비즈니스에 접목시킬지, 또는 비교적 간단한 모델로 어떻게 실질적인 가치를 만들어낼지에 더 많은 관심을 두고 있었다. 이러한 프로젝트에서는 플랫폼 차원에서 범용적인 추상화를 시도하기보다는, 개별적으로 배포나 트러블슈팅을 지원할 수밖에 없었다. 다만 돌아보면, 당시 대부분의 프로덕트가 구상 단계에 있었고, 업무의 범주가 확장되고 정리되는 초기 과정에 있었기 때문이었다. ML제품은 결국 실험을 통해 개선되고 전달된다. 이때 광고타겟팅과 추천시스템 같은 일반적인 ML서비스의 구조에 대해 잘 이해하고, 앞으로 만들어질 것들과 실험의 중요성을 인지하고 있었다면 더 좋은 판단을 할 수 있었을 것이다. 앞선 생각으로 리드 분과 이야기를 나눴던 적도 있는데, 당시 큰 그림에 공감하고 긴 호흡으로 기여하지 못한 점이 아쉬움으로 남는다.
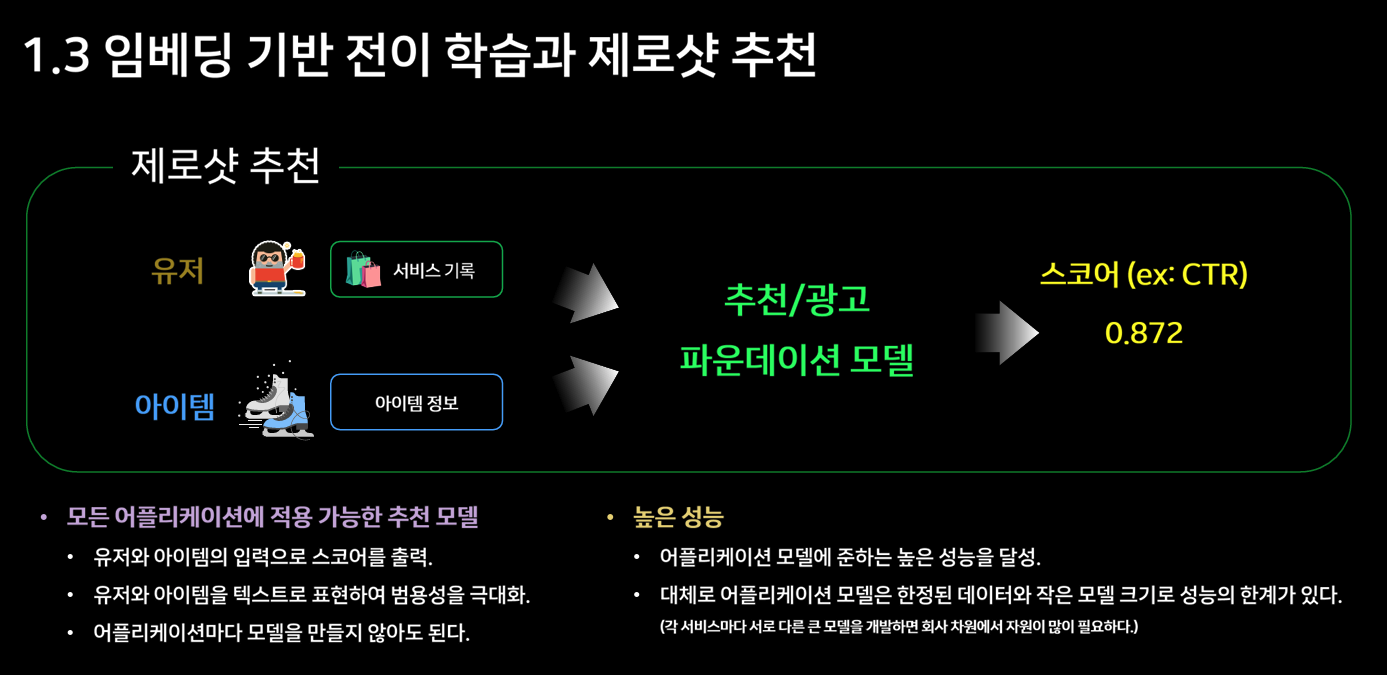
그렇게 자연스럽게 MLE 혹은 데이터 엔지니어 포지션을 다시 살펴보게 되었다. 눈에 띄는 변화는 채용 공고 대부분에 LLM 언급이 중심적으로 등장하고 있다는 점이었다. 오랜만에 들어가기 시작한 링크드인에도 Building LLMs @어떤 회사 계정이 많이 보였다. LLM의 등장은 이미 업계 전반에 걸친 지각 변동으로 예견되어 있었지만, 내가 퇴사를 결심했던 시점은 LLM 기반 프로덕트가 본격적으로 적용되기 시작하던 초기 단계였다. 이후 사이드 프로젝트를 진행하며 ChatGPT를 활용해 왔지만, 당시에는 개발자로 커리어를 계속 이어갈 생각이 아니었기에 sLLM, RAG, AI Agent와 같은 관련 기술 흐름에는 깊은 관심을 두지 못했다. 해외에 있는 시간이 지나고 나면 LLM이 더 부각될거라 생각해서, 주어진 시간 안에 관련 자료와 적용 사례를 찾아보았고 어느 정도 공부와 적당한 핸즈온 경험을 쌓기로 마음먹게 되었다.
LLM, RAG, AI Agent?
개인적으로 블로그에는 많은 설명을 하기 보다는 최대한 탑다운 방식으로 내용 정리를 하려 합니다.
접근 방법
위 기술의 아주 일반적인 사례는 제외하고, 인상적인 사례들을 찾아보고 내용을 요약해보려 한다. RAG, AI Agent가 발전해온 과정은 생략한다. 또한 파인튜닝이나 파운데이션 모델 구조를 분석해야하는 내용보다, 어떻게 버티컬서비스에 적용하고 있는가를 기준으로 훑어보려 한다. Eugene Yan의 블로그와 VESSL AI의 유튜브가 큰 도움이 되었다.
Amazon
음악 플레이리스트 검색 시스템 개선
https://dl.acm.org/doi/10.1145/3640457.3688047
기존에 키워드 매칭 기반 플레이리스트 검색 시스템을 LLM을 이용해 시멘틱 검색 모델로 개선했다.
문제점
- 커뮤니티의 플레이리스트는 메타데이터가 부족한 경우가 많아서 시멘틱 검색 모델 학습에 어려움이 있었다.
- 기존 훈련데이터
<검색어, 클릭된 플레이리스트>데이터가 신규(시멘틱 검색) 모델 학습에 적합하지 않다. - 모델 성능을 평가하기 위한 라벨링 작업이 비싸다.
해결방법
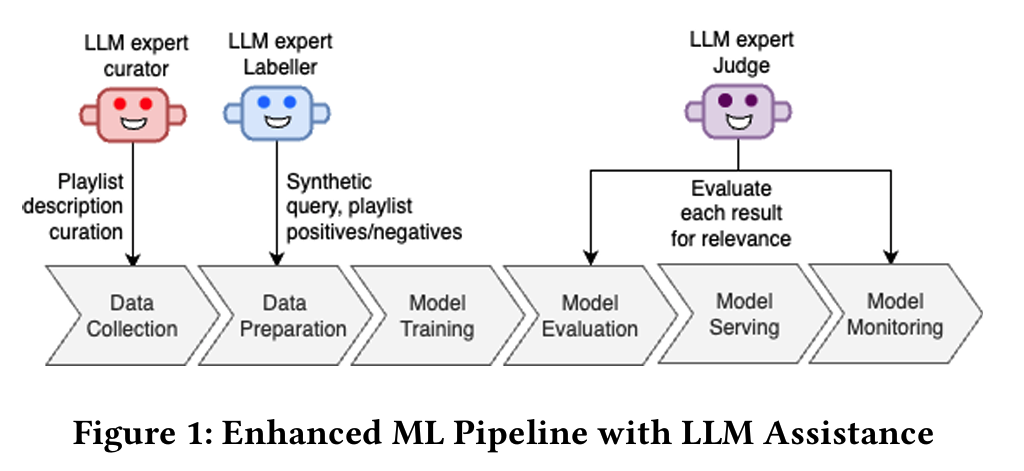
- 메타데이터가 부족한 플레이리스트는 LLM 큐레이터 모델이 첫 15곡을 기반으로 상세설명을 생성한다.
- 이는 30B 모델을 파인튜닝해 사용함. 에디터 플레이리스트와 설명이 존재하는 플레이리스트 데이터를 이용함.
- LLM 라벨러 모델을 통해 학습데이터를 생성했다.
- 플레이리스트 메타데이터를 통해 검색어를 생성한다.
- 로그의 검색율이 좋지 않았던 검색어를 이용해 플레이리스트를 찾아내어 ‘어려운’ 검색어에 대한 학습 데이터를 추가한다.
- 이 과정에서는 아마존 자체 텍스트 임베딩과 작은 LLM 모델을 사용한다. (자세히 설명하지 않음)
- 생성된 학습 데이터에 대해 라벨러가 Positive/Negative 라벨링을 한다.
- LLM 심사관을 통해 평가를 자동화한다.
- 자세한 설명은 없다.
- 데일리 모니터링에도 사용함.
참고: LLM-as-Judge
 https://eugeneyan.com/writing/llm-evaluators
https://eugeneyan.com/writing/llm-evaluators
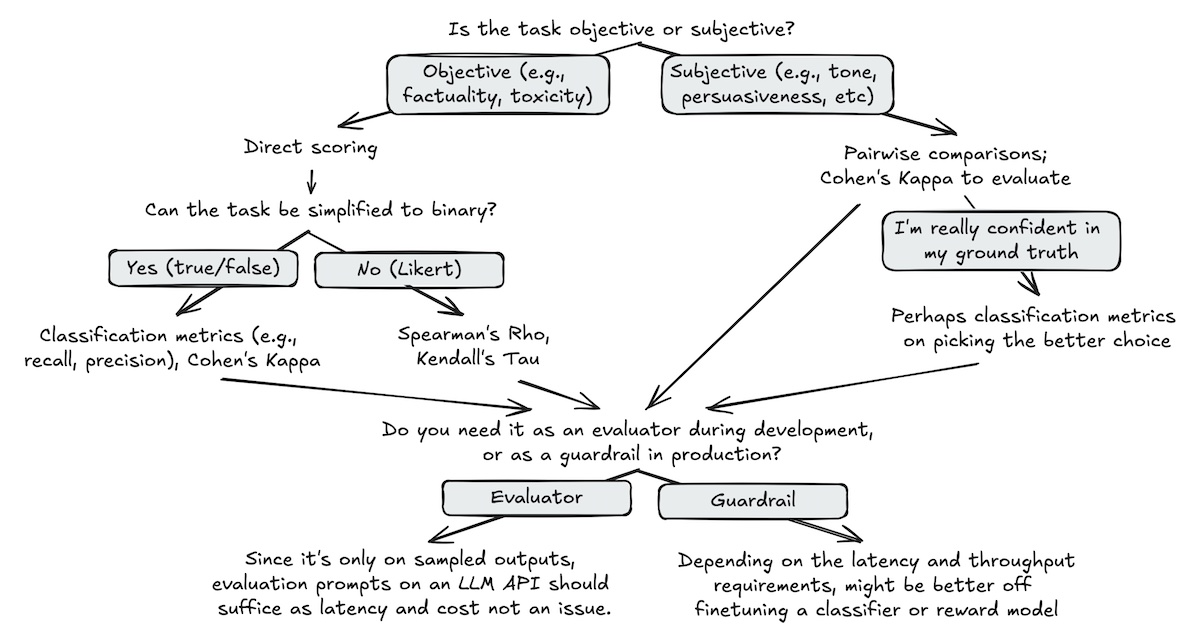
평가 방법
- Direct scoring (객관적 평가에 적합)
- Pairwise comparison (주관적 평가에 적합)
- Reference-based (응답에 포함되어야 할 정보를 비교)
평가자 평가방법
- 분류 기반 지표 (precision, recall, …)
- 해석 용이
- 상관(correlation) 기반 지표
- kappa, tau, rho
- 우연한 일치를 고려하지 않거나, 제품 성능으로 직결하기 어려워 최대한 분류 기반 지표를 사용하는게 좋음
장점
- 인간 평가보다 비용이 적게 들고 빠르다.
- 모델, 랜덤 시드와 하이퍼 파라미터가 같다면 같은 평가의 재현성이 높다.
- 확장 가능하여 모니터링에 사용할 수 있다.
주의점
- LLM 평가가 신뢰할 수 있는지 검증하려면, 일부 샘플에 대해 사람 평가와 비교해야한다.
- 앙상블 방식으로 여러 평가 모델을 사용해 편향을 줄이고 안정화 시킬 수 있다.
- 순서를 랜덤화해서 LLM이 첫 번째와 마지막 질문에 집중하는 bias를 줄여야 함
- LLM이 짧은 답변 선호 경향이 있다. 선호도의 기준에 대한 지시를 명확히 하는게 좋다.
- CoT: 최종 판단 전에 이유나 단계별 분석을 설명하도록 요구한다.
Text-to-SQL 시스템
https://medium.com/pinterest-engineering/how-we-built-text-to-sql-at-pinterest-30bad30dabff
문제점
- 다양한 도메인에 데이터가 퍼져있는 환경에서 정확하고 효율적인 SQL 코드를 짜는 것은 어렵다.
해결방법
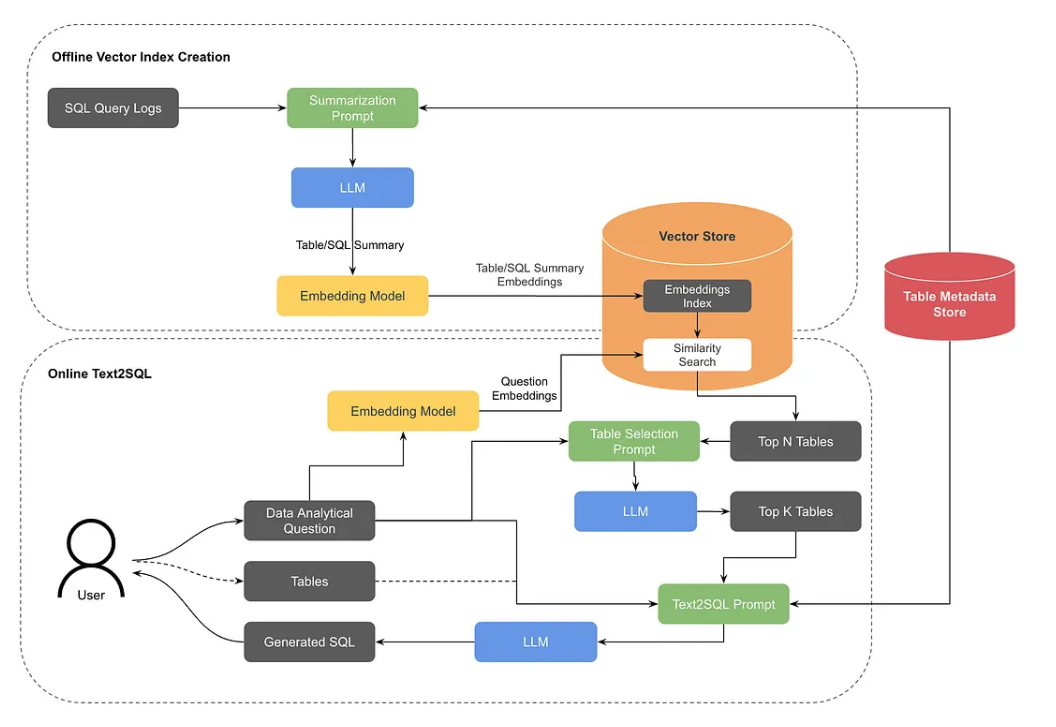
- 분석적 질문을 SQL 코드로 변환해주는 모델을 만들었다.
- 테이블을 찾는 것조차 시간이 많이 걸리기 때문에 RAG를 통해 테이블을 특정해주는 구조로 만들었다.
- 테이블에 대한 쿼리 히스토리와 LLM으로 만들어진 테이블 설명을 합쳐서 임베딩으로 만든다.
- 분석 질문을 임베딩해 유사도 검색으로 테이블 Top N개를 구한다.
- 위 테이블 N개를 프롬프트에 넣어서 Top K개의 테이블로 줄이고, 이 중 유저가 선택한다.
- 이후 분석질문과 테이블을 이용한 프롬프트로 SQL 코드를 만든다.
- 각종 프롬프트는 여기 공개하고 있다.
- https://github.com/pinterest/querybook/tree/master/querybook/server/lib/ai_assistant/prompts
- RAG 검색에는 데이터 거버넌스팀이 작성한 테이블 메타데이터가 영향이 컸음.
- 기본적인 테이블 메타데이터를 이용한 프롬프트 시스템에서 분석가들의 쿼리 생성속도가 30% 빨라졌다.
VESSL AI
Customer Support Agent 개발
https://youtu.be/3H_SGpyhfco?si=oxs56ky0WYj1hPBX
공식 문서, 서포트 기록, 내부 기술 문서, 샘플 코드 등 다양한 내부 자료를 기반으로 서포트 에이전트를 제공한다.
문제점
- 다양한 형태와 출처의 데이터를 정제하여 적재하는 과정이 어렵다. 모아진 비정형 데이터로는 환각현상이 심하다.
- 사람의 팔로우업이 필요하다고 스스로 판단하고 알림을 주어야 한다.
해결방법
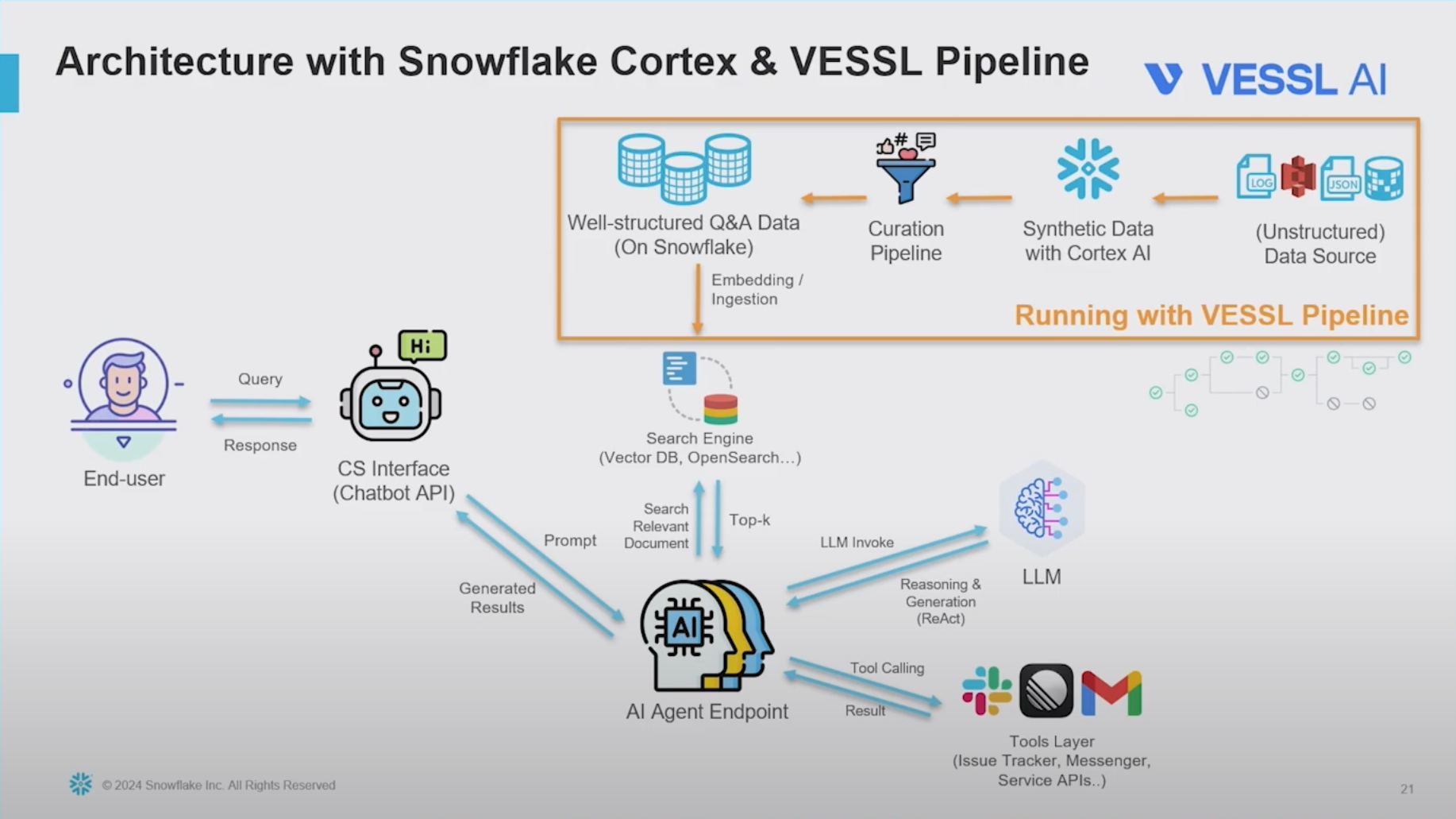
- Snoflake Cortex라는 합성 데이터(Synthetic Data) 생성을 위한 LLM 기반 파이프라인을 도입한다.
- 기존 모델이 추론용 LLM에게 재질문을 하거나 슬랙 등의 API 호출을 할 수 있도록 만든다.(이 부분은 설명하지 않고 넘어갔다.) 평가
- 좋아요 누른 고객 20% 증가
- 응답시간 1/3로 감소
참고: 합성 데이터 생성

- 흐릿해서 잘 안보이는데, 결과적으로 만들어진 정형 데이터는 Question, Answer, code_example, reference로 이루어진다.
- 합성데이터 생성은 snowflake cortex로 처리한다. 도큐먼트를 살펴보면 snowflake는 관리형 DB를 가지고 있는 장점을 이용해 SQL 인터페이스로 LLM발 데이터 생성과 적재를 제공한다.
- 이 데이터에 대한 사람의 검증과정과 재현 가능성을 강조하는데, 이 부분은 직접 구현한 툴로 해결했다고 한다.
네이버
웹툰 데이터 구조화
https://cn.blockchain.news/news/webtoon-enhances-story-understanding-langgraph-ai
위 뉴스말고 4월 23일에 LangChain 블로그에 올라온 글이 있었는데 지금은 내려간 것으로 보인다.
Webtoon Comprehension AI(WCAI) 이라고 부르는 시스템으로, VLM을 이용해 웹툰의 캐릭터를 식별하고, 화자를 인식해 내러티브를 추출하고 웹툰을 구조화된 데이터로 변환했다고 한다.
이를 통해 의사결정에 도움을 받고, 아마도 모델 피쳐로도 사용한 것 같다.
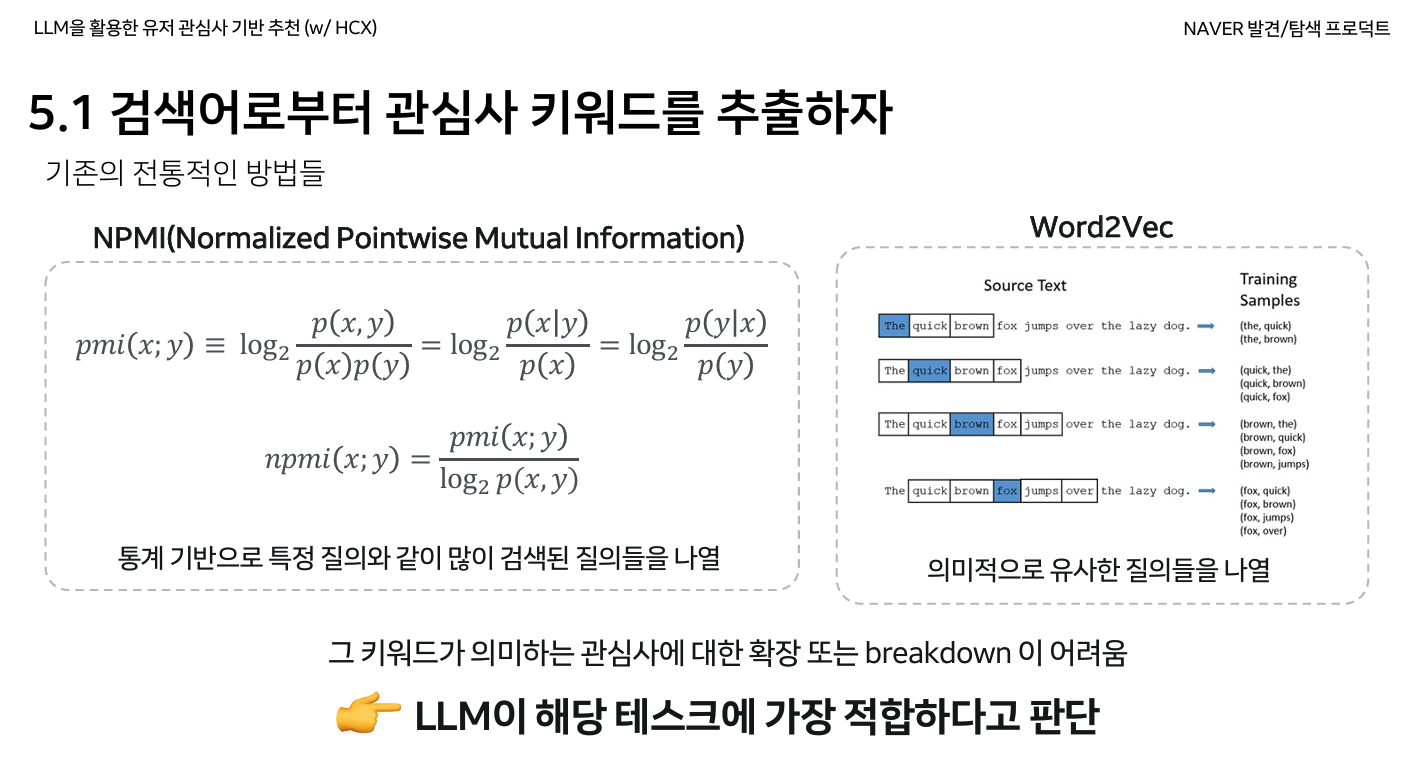
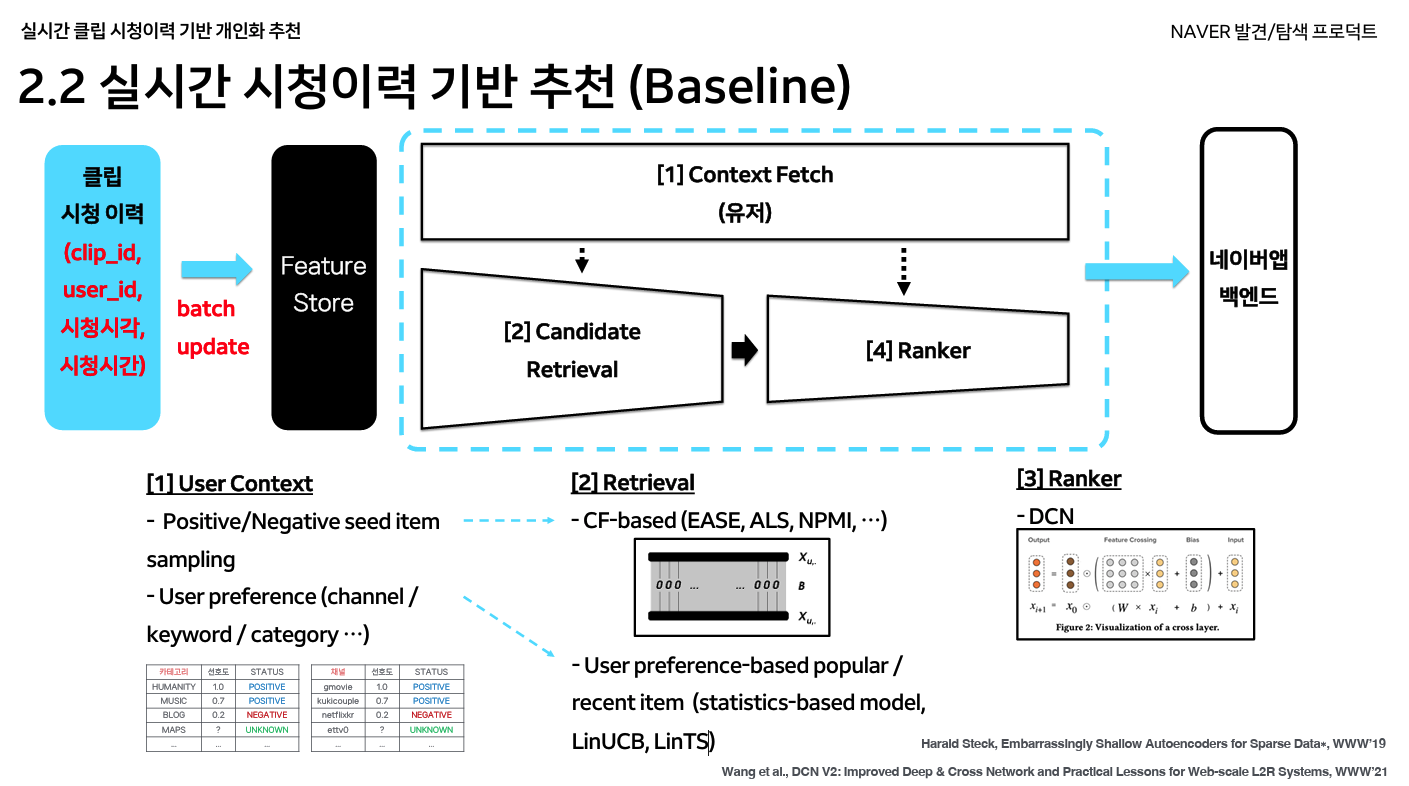
숏폼 영상 추천 시스템
https://dan.naver.com/24/sessions/624

- 새로운 서비스이기에 콜드스타트 문제가 있다.
- 기존에는 사용자의 검색 이력을 형태소 분석, 클립의 키워드와 카테고리 기반 매칭했는데, 이를 LLM 기반으로 개선했다.
- 장표의 HCX는 HyperCLOVA X라고 한다
문제점
- “하수구 막힘” 등 탐색형 질의 검색어에도 영향을 받음
- 검색어에 국한된 결과만 추천되어 확장된 관심사를 캐치할 수 없음
- “볼리비아 비자”, “이과수 폭포” 등을 검새하면 아르헨티나 여행에 관심이 있는 것인데, 이 컨텍스트를 파악할 수 없음
해결방법
- LLM으로 관심사 키워드를 추출한다.
- LLM의 최신 데이터 부족으로 최신 드라마, 배우 등을 잘 모르는 이슈가 있는데, 이건 사내 Named Entity Tagger를 이용함.
- 탐색형 질의는 질의의 entropy, topic, intent 데이터를 활용해 처리 (어떻게 구했는지는 설명하지 않음)
- 관심사 키워드 매칭을 아직 이용하는데, 임베딩으로 변환해 고도화하려고 한다.
DAN24에서 나온 좋은 슬라이드 모음
https://dan.naver.com/24/sessions
이외에도 여러가지 발표가 있는데, 네이버의 발표는 특정 실험과 시스템을 소개하기보다 발표마다 여러 명이 나와서 각 조직에서 하고 있는 일을 전부 on-going 상황까지 설명한다는 느낌이 있어서 나같은 사람보다는 유사한 프로젝트를 진행 중인 회사 개발자들이 보는게 유익한 것 같다. 그래도 내용이 많다보니 참고하기 좋은 슬라이드가 꽤 있는데, 아래 첨부했다.
펼치기



당근
전문판매업자(어뷰저) 자동 신고 시스템
https://youtu.be/UGjRhqZygHg?si=yxp3gkZl_AVUQqTj
Supervised Learning 방식의 문제점
- 발견되기 전까지 학습데이터에 반영할 수 없다.
- 다량의 데이터가 필요해 빠르게 바뀌는 패턴을 학습하기 어렵다.
- 어뷰저의 패턴이 매우 다양하다.
해결방법
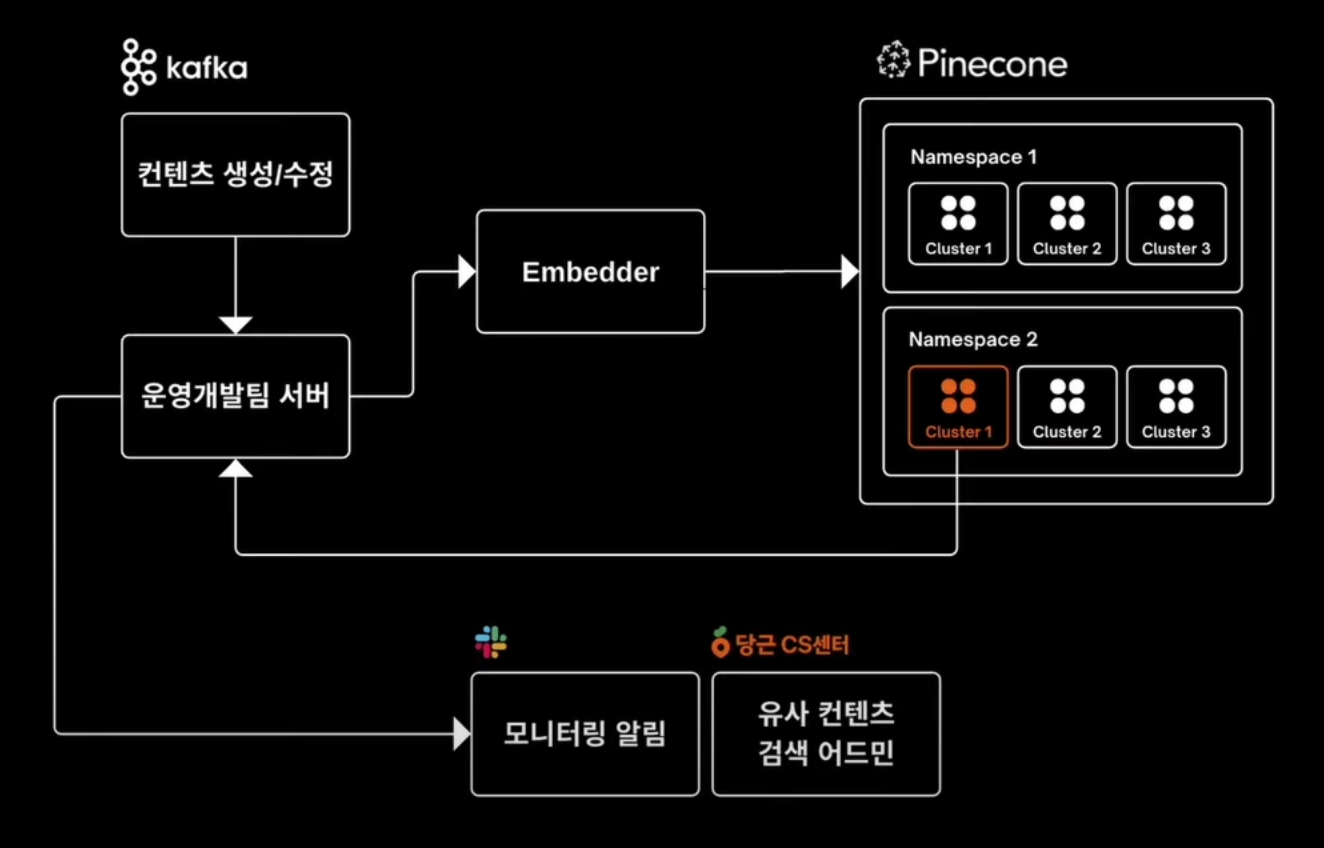
- 유사컨텐츠 로직
- 판매글 이미지와 임베딩과 텍스트 임베딩을 Pinecone에서 클러스터링하고, 클러스터 사이즈에 기반하여 유사도가 높은 글은 알림을 받는다.
- 언급된 “파인콘 내부 로직에 따른 클러스터링”이 무엇인지 확실히는 모르겠으나 아마도 파인콘이 제공하는 유사도 검색을 그렇게 표현한 것 같다. 파인콘 Q&A 에이전트에 따르면 클러스터와 그래프 인덱싱이 모두 사용된 혼합형 알고리즘을 직접 개발해서 사용한다고 한다.
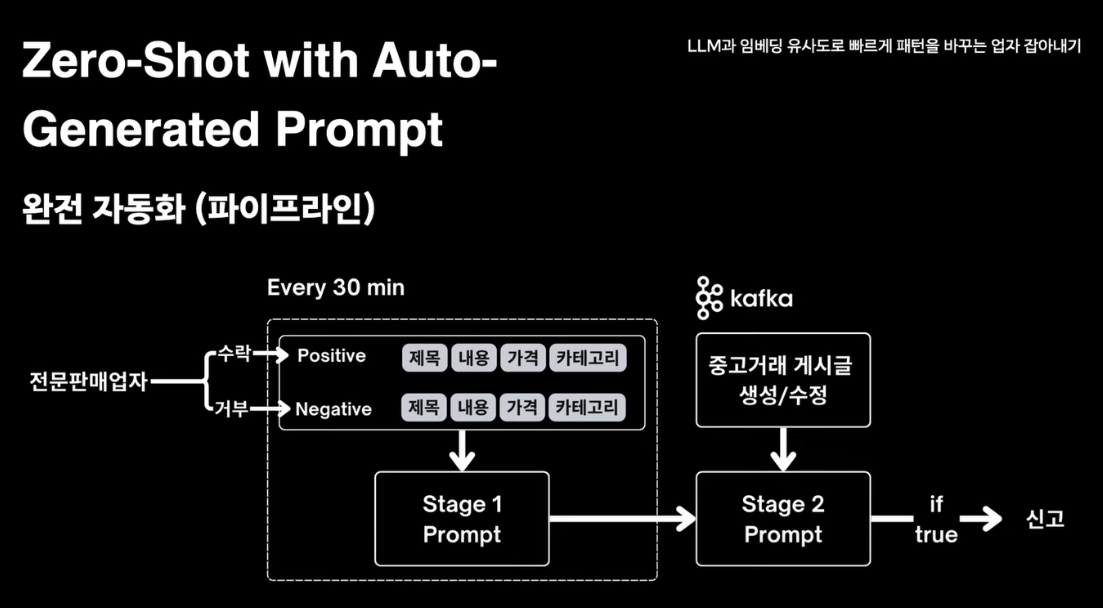
- Zero-Shot with Auto-Generated Prompt를 통한 분류
- 신고된 글 중 Positive 100개와 Negative 100개 게시글을 프롬프트에 전달해 특징을 추출한다.
- 새 게시글이 생성될 때 위에서 추출한 특징을 이용해 전문판매업자인지 분류하도록 한다.
성과
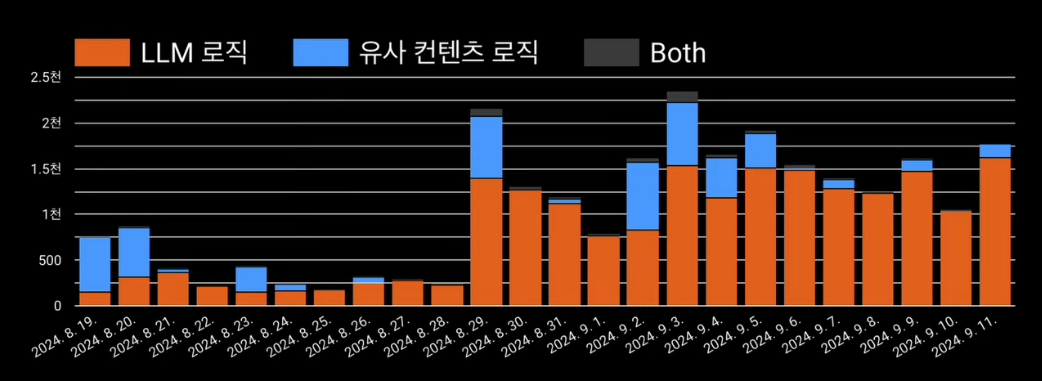
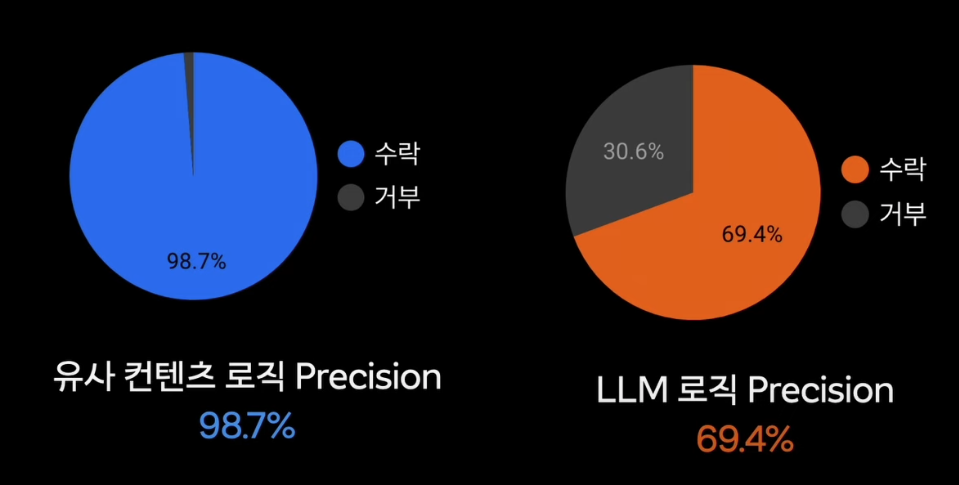
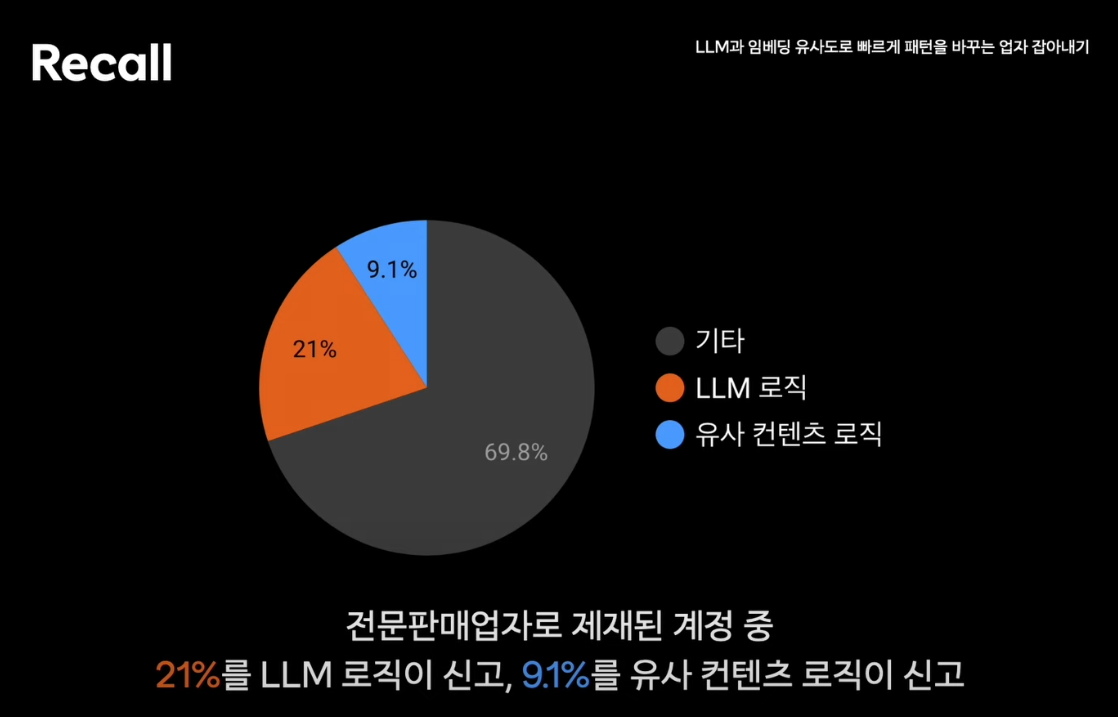
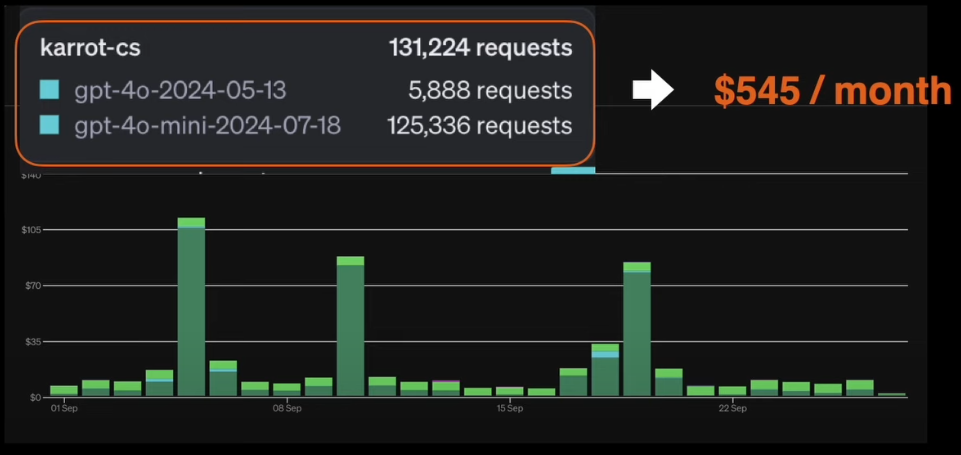
- 유사컨텐츠 로직으로 선제적인 모니터링 가능
- Zero-Shot with Auto-Generated Prompt를 통해 적은 라벨링 데이터로 패턴 탐지 가능
- 자동 감지 신고 수 높아짐, Precision 높음, 사용자의 신고 수 줄어듬
- 호출비용 매월 $545
- 정황상 특징 추출은 gpt-4o, 분류는 gpt-4o-mini로 한 것으로 보인다.
참고: HNSW 인덱스에 insert할 때 벌어지는 일
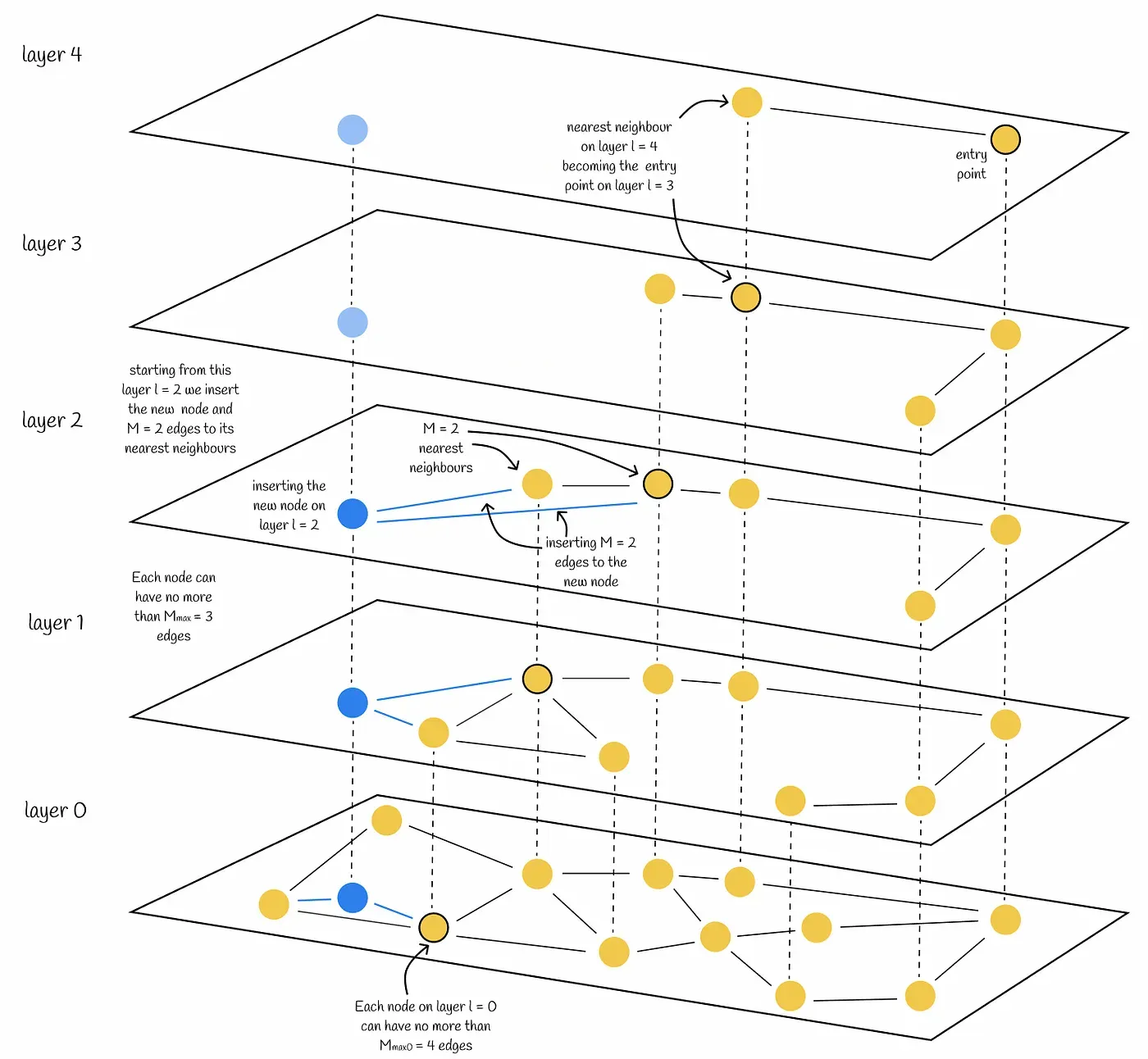 https://towardsdatascience.com/similarity-search-part-4-hierarchical-navigable-small-world-hnsw-2aad4fe87d37/?ref=pangyoalto.com
https://towardsdatascience.com/similarity-search-part-4-hierarchical-navigable-small-world-hnsw-2aad4fe87d37/?ref=pangyoalto.com
- 새 백터 생성, 레벨 랜덤 결정
- 지수분포 확률에 따라 새 벡터의 레벨이 정해지고, 현재 인덱스의 가장 높은 레벨의 Entry Point를 선택한다.
- Entry Point 선택
- 현재 인덱스의 가장 높은 레벨의 Entry Point를 선택한다.
- 각 레벨에서 Greedy Search로 근접 이웃 찾기
- 현재 노드의 이웃 중 가까운 노드를 찾아가며 새 벡터에 가까운 local minimum에 도달한다.
- 이 때 이웃을 탐색하는 넓이는 하이퍼파라미터로 설정한다.(efConstruction)
- 이웃 설정 후 간선 연결
- 설정한 하이퍼 파라미터 개수만큼 가까운 이웃을 찾고 연결한다.
- 레벨 0까지 반복 후 삽입 완료
- 위는 그래프 인덱스 방식, IVF 등은 클러스터(파티션) 기반 인덱싱으로 설정된 수만큼 클러스터와 centroid를 갖고, 역인덱스 방식으로 (centroid -> 벡터 ID 리스트) 구조를 갖고, 삽입 시 L2 거리 기준 벡터가 속한 클러스터에 append 된다.
- IVF+HNSW 같은 Mixed index는 클러스터를 먼저 탐색 후 centroid가 entrypoint가 되는 그래프 구조다.
동네업체 추천 서비스
https://medium.com/daangn/rag를-활용한-검색-서비스-만들기-211930ec74a1
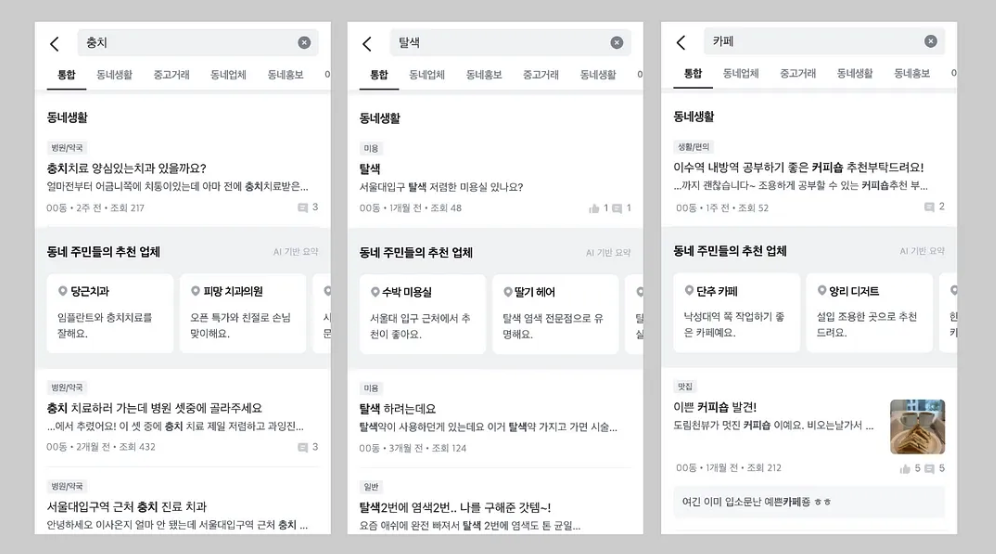
문제점
- “용달”, “동물병원” 등 업체가 동네생활 상위 검색어인데, 유저들은 이를 생활 게시물을 살펴보고 직접 취합해야하는 과정을 거쳐야 한다.
해결방법
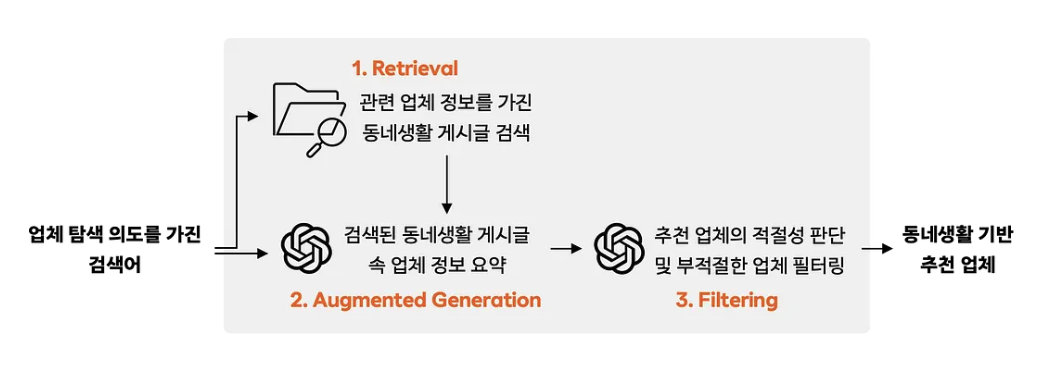
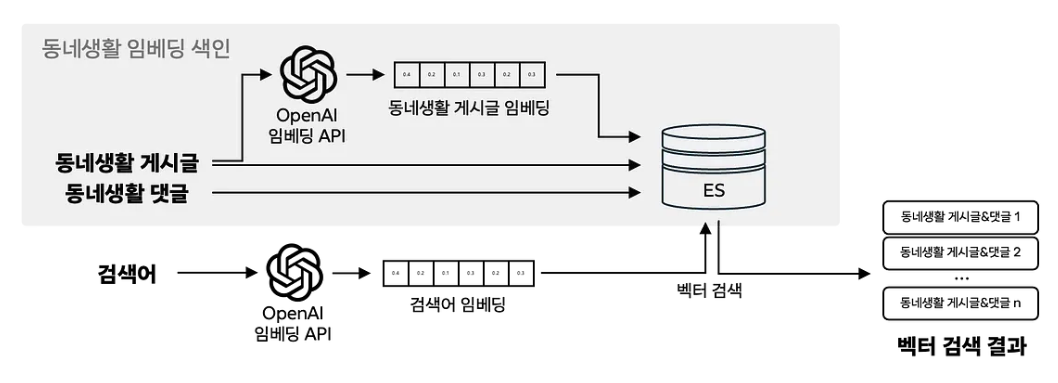
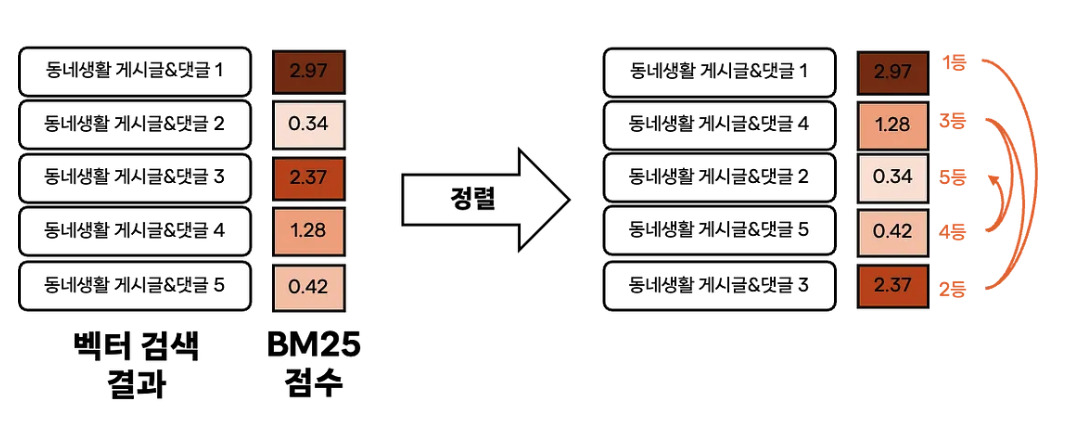
- 게시글을 OpenAI API를 통해 임베딩 후, 댓글과 함께 ES에 저장한다.
- 검색이 발생하면 검색어를 같은 API로 임베딩 후 ANN을 통해 유사도 검색을 수행한다. 이 때 메트릭은 코사인 유사도다.
- 여기서 검색된 문서를 업체를 추출하는 프롬프트에 포함시키는데, BM25 스코어를 계산해서 랭킹을 매긴 후, 위 아래 왔다갔다하며 문서를 위치시킨다.
- LLM은 시작과 끝 부분에 더 집중하는 특성이 있기 때문이라고 한다.
- 게시글과 댓글은 JSON 형식으로 구조화시켜 프롬프트에 삽입한다. 이를 더 잘 분석해주었다고 한다.
- Structured Output API를 통해 업체와 정보 요약문을 생성한다.
- 부정적 내용 검증, 관련성 검증, 추천된 업체 리스트에 중복이 있는지 체크하는 스테이지를 두어 검색어와 업체가 관련이 있는지 판단한다.
LLM을 통한 게시글 피쳐 추출과 추천
https://medium.com/daangn/당근에서-llm-활용하기-76131ecebce1
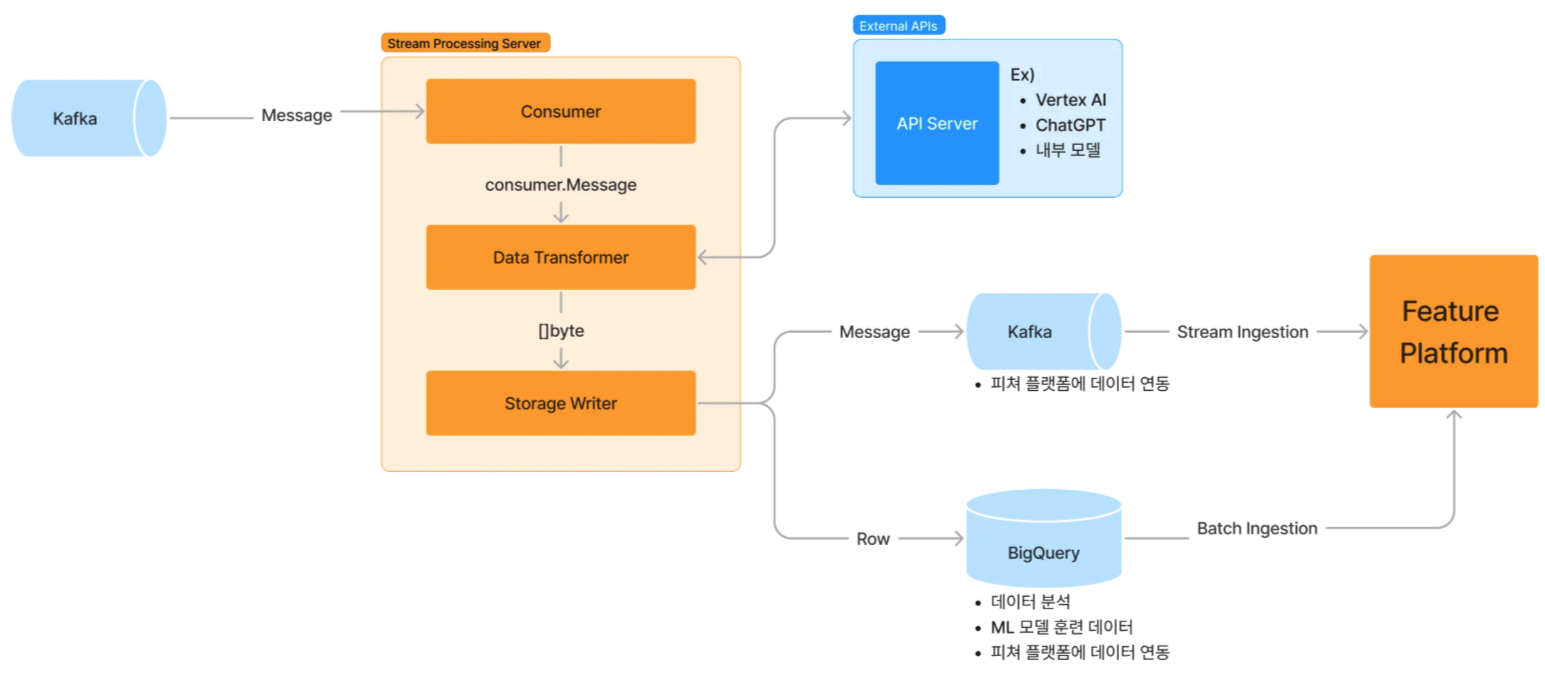
- 중고판매글에서 판매 아이템의 브랜드, 사이즈, 세부 카테고리를 추출하여 추천에 사용
- 장소 언급은 있지만 장소 태깅이 안된 글에서 “언급된 장소” 추출
- 모임의 이름과 설명을 보고 나이대, 성별, 세부 카테고리 추출 후 추천에 사용
- 부동산 판매글 작성 시 줄글을 보고 복잡한 입력폼에 입력 자동화
참고
- 프롬프트 테스트셋을 만들고 반복 개선 필요
- 프롬프트나 모델의 변경 시 평가와 배포 자동화, 변경 관리, 비용 추적, A/B 테스트 필요
고객지원 에이전트 시스템
https://medium.com/daangn/지금의-방식이-최선일까-ai로-임팩트를-바꾸는-당근-운영실-289e6c1ba987
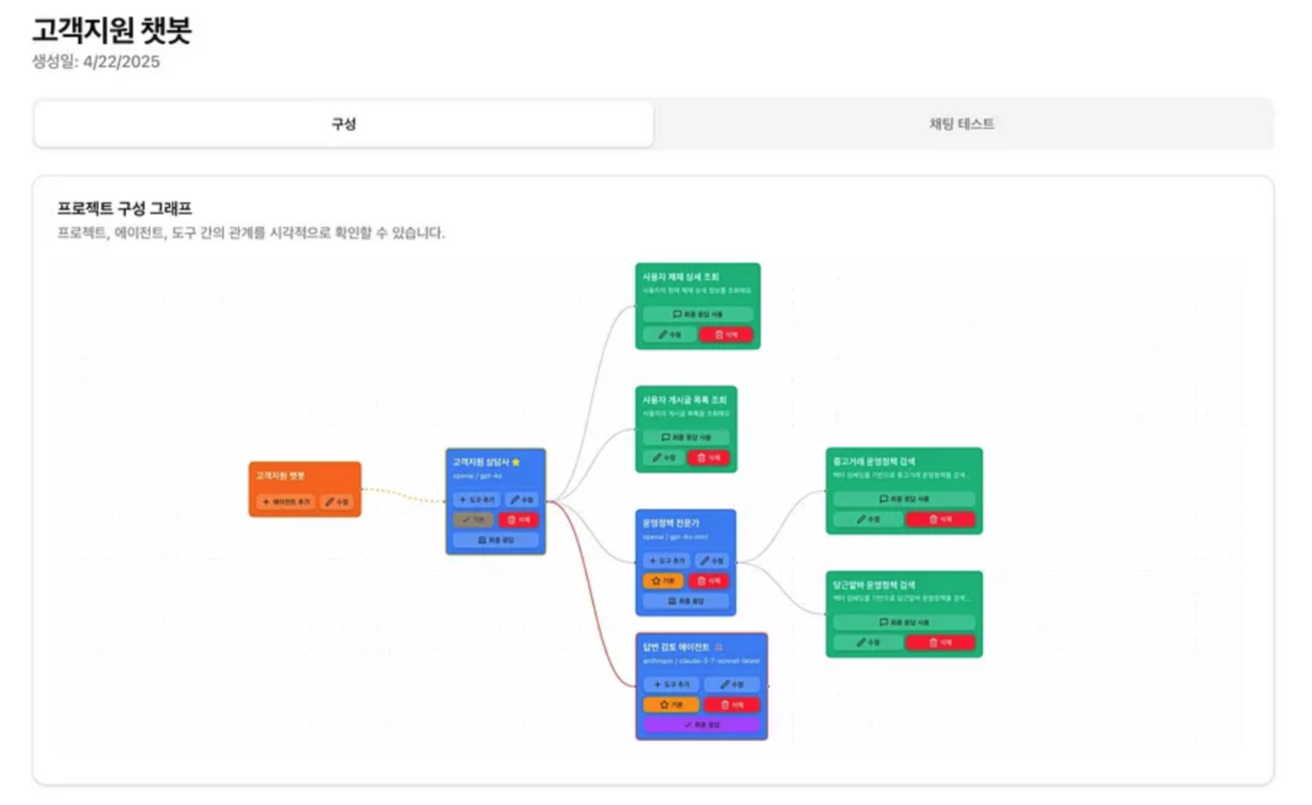
- 구조 설명이 목적인 글이 아니라서 각 단계가 어떻게 구현되었는지는 알 수 없다. 글만 봤을 때는 dify.ai와 유사한 툴을 구현하고 있는 것 같다.
- Vessl AI의 예시와 유사하지만 서포트 케이스와 고객의 데이터의 분류가 다양하기 때문에, 다양한 데이터 소스를 두고 있고, Agentic RAG의 구조도 포한하고 있는 것으로 보인다.
- 당근의 다른 사례들을 봤을 때 파인튜닝한 sLLM을 결합하는 멀티에이전트시스템을 말한 것 같지는 않고, 모델의 비용, 추론 능력에 따라 다양하게 사용하기 위해 나눈 것으로 보인다.
전체적으로 당근은 비정형 데이터가 핵심이 되는 비즈니스를 하고 있기 때문인지 정형데이터 생성과 활용을 여러 사례에서 보여준다.
개발자 구직 에이전트?
다음 글에서…
핸즈온으로 찹찹이라는 웹을 개발했다. 다음 글에서 볼 수 있다.