Dmitry Vyukov의 발표 영상을 요약한 글이다.
Java thread의 갯수는 아무리 많아도 수만을 넘지 못하지만, Goroutine은 수백만을 유지할 수 있다. 어떻게 가능할까? 결론부터 말하자면 이유는 크게 두 가지로, 유저 스페이스에서 작동하는 M:N 스케줄러와 가변 스택 덕이다.
Go Scheduler
M:P:N threading
.Net이나 Java와 같은 환경에서 특별히 최적화되지 않은 user thread는 kernel thread와 1:1 매핑된다. 하지만, Go의 개발자들은 고루틴을 백만 개 이상 안정적으로 스케일하길 원했고, M:N 매핑(정확히는 M:P:N)을 사용했다.
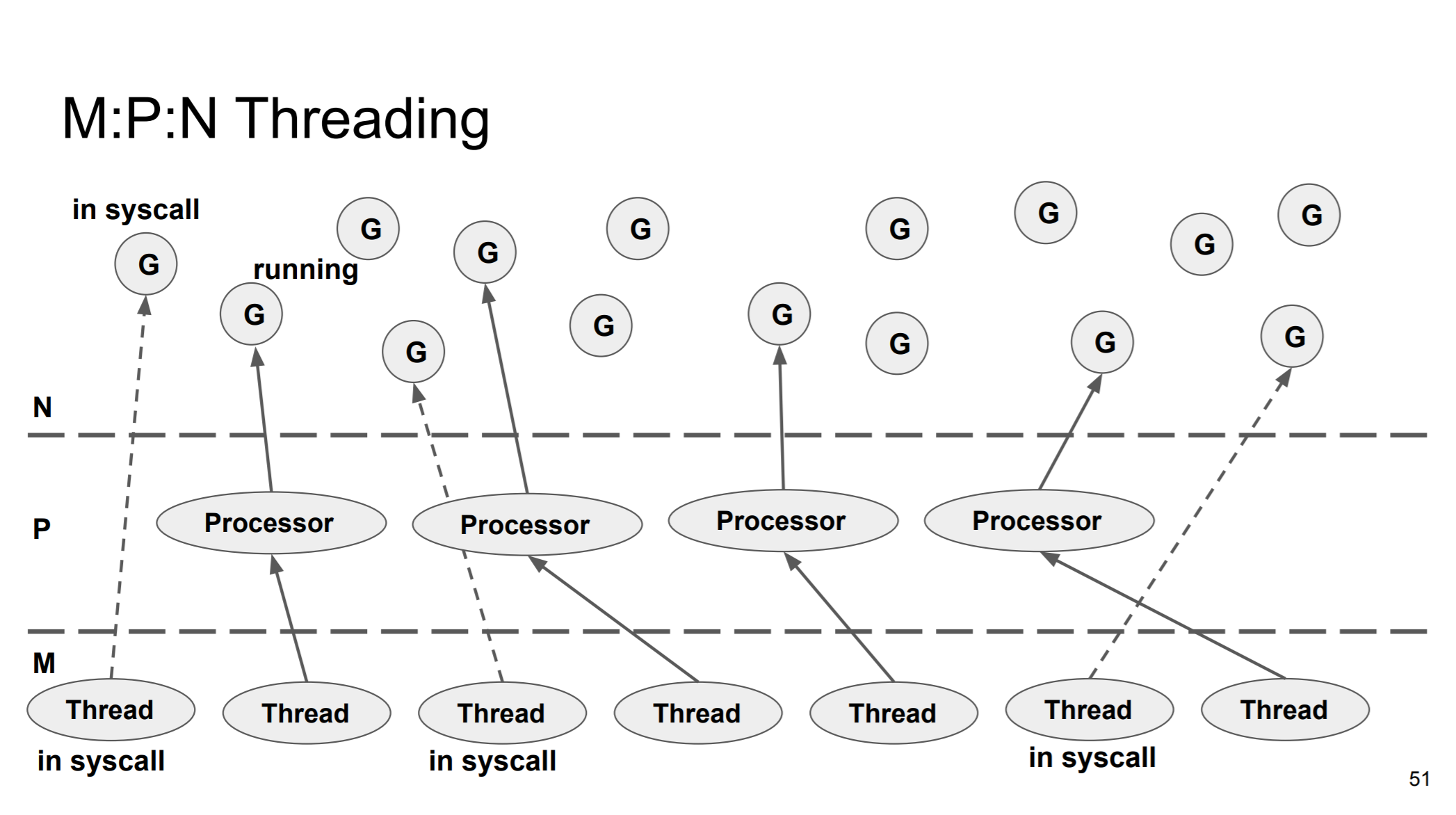
고루틴과 커널스레드가 1:1 매핑이 아니므로, 실행가능 상태인 고루틴이 보관될 큐가 필요한데, Go는 스레드가 아닌 프로세서 객체마다 존재하는 Local Run Queue(이하 LRQ), 그리고 Global Run Queue(이하 GRQ)를 구현했다. 채널이 런타임에 제어되고 채널마다 Wait Queue가 따로 있으므로 전체적인 Wait Queue는 추가로 필요하지 않다. 네트워크 응답 대기 상태인 고루틴은 Network Poller가 관리한다.
M:N이 아닌 M:P:N 형태로 구현한 이유는 Work Stealing에 있다. Work Stealing이란 실행 중인 스레드가 다음 고루틴을 선택할 때 다른 스레드의 LRQ를 확인하여 실행 준비 상태의 고루틴을 가져오는 것을 말하는데, #threads » #cores이기 때문에 스레드마다 LRQ를 가지고 Work Stealing을 위해 서로서로 모두 확인하게 하려면 시간이 오래 걸리게 되어 비효율적이다. 그러므로 코어 수와 동일한 수의 프로세서 객체를 만들어 스레드가 아닌 프로세서 객체가 LRQ를 가지고 있게 하여 효율적으로 고루틴을 스케줄링하도록 구현됐다.
Poll order
다음 순서에 실행될 고루틴은 어떻게 고를까?
프로세서가 선택할 수 있는 고루틴은 여러 종류가 있다.
- Local Run Queue
- Global Run Queue
- Invoke Network poller
- Work Stealing
Starvation을 다루기 위해 뒤에 설명할 디테일이 있지만, 거시적으로는 아래 순서와 같다.
- 프로세서 자신의 LRQ를 확인하여 고루틴을 pop
- 자신의 LRQ, GRQ가 비어있으면 다른 프로세서의 LRQ에서 고루틴을 pop(work stealing)
- GRQ를 확인하여 고루틴을 pop
- System Call을 실행한 고루틴은 스레드가 해제되고, 기다리다가 반환 값이 왔을 때 큐로 들어간다.
- Network I/O를 실행한 고루틴은 Network Poller로 배정되어 기다리다가 결과가 왔을 때 큐로 들어간다.
Fairness and handling starvation
Fairness란 실행 대기 상태인 고루틴은 언젠가 실행되어야 함을 의미한다. 이를 만족하지 않을 때 Starvation이 일어난다.
Starvation은 고루틴, LRQ, GRQ, Network Poller마다 일어날 조건이 다르며, 해결하는 방법도 제각각이다.
Time slice based preemption
- 하나의 고루틴이 프로세서를 오래 점유하는 것을 막기 위해 기본 10ms의 time slice가 정의되어 시간을 넘겼을 때 실행 중이던 고루틴은 preempted되어 GRQ로 들어간다.
FIFO Run Queue + 1-element LIFO buffer
- FIFO Queue는 Fairness를 만족할 수 있지만, LIFO보다 Locality 관점에서 비효율적이며, Work Steal 당했을 경우에 프로세서 스테이트를 잃어버리므로 좋지 않다.
- 예를 들어 하나의 고루틴이 실행 후 새로운 고루틴을 생성할 경우, 새 고루틴을 바로 실행하여 프로세서의 캐시, 스택 등을 바로 사용할 수 있으면 좋은데, 이를 만족하기 위해 LRQ에는 1-element LIFO buffer가 있다.
- 고루틴 1이 고루틴 2를 생성했을 때 3ms동안 다른 프로세서로부터의 work stealing을 방지하고 실행할 수 있도록 한다.
- 이 방법 또한 고루틴 생성 순환이 생겼을 경우 Starvation을 일으키는데, time slice inheritance가 일어나 buffer에서 지속적으로 꺼내는 것을 막고 preempt 시킨다.
Global Run Queue Starvation
- LRQ만 계속 확인하고 GRQ polling이 일어나지 않을 수 있다.
- schedTick 변수가 존재하여, 61번의 polling이 일어날 때마다 LRQ->GRQ 순으로 확인하지 않고 GRQ를 먼저 확인하여 polling한다.
- schedTick 값이 61인 이유는 일단 실험적으로 성능이 좋았던 값의 범위 안에서 prime number를 고른 것이다. prime number를 사용한 이유는 hash map에서 균일 분포를 위해 prime length를 사용하던 것과 마찬가지로 어플리케이션 패턴과의 충돌을 피하기 위함이다.
Network Poller Starvation
- time slice가지고 핸들링할수도 있겠지만 network poller는 systemcall을 동반하므로 좋은 방법이 아니다.
- 백그라운드 스레드를 하나 배치하여 관리한다.
Fairness Hierarchy
- Goroutine - preemption
- local run queue - time slice inheritance
- global run queue - check once in a while
- network poller - background thread
=> minimal fairness at minimal cost
Contiguous Stack
백만 이상의 고루틴을 생성하려면 infinite stack이 필요하다. 일반적으로 스레드당 stack은 1~8mb (but stack is cheap, rsp 값을 바꿀 뿐이다).
- infinite stacks은 일반적으로 1GB 정도를 만족하면 된다.
- 64bit OS에서 CPU address space를 48bit가 표현하며 이는 128TB를 구현할 수 있는데, 위와 같은 mb 단위 스택을 스레드마다 할당하면 최대 128K 스택 밖에 확보하지 못한다. => paging-based stack won’t work
Split Stack
- 1KB짜리 stack segment를 차례차례 할당한다.
- normal function call ~2ns
- stack split ~60ns
빠른 forloop안에 함수 호출이 있을 경우 stack split의 영향이 너무 크다. stack split이 일어나냐 안 일어나냐에 따라 좌지우지됨. non-transparent performance
Growable Stack
- allocates new large stack, copy the old stack and releases
- shrink when gc cycle
Split Stack vs Growable Stack
split stack
- O(1) cost per function call
- repeated
- worst case: stack split in hot loop
growable stack
- O(N) cost per function call
- amortized
- worst case: grow stack for short goroutine
Penalizing cheap operation a bit < penalizing expensive operation significantly
사실 이렇게 말하면 Growable Stack에도 non-transparent performance 문제는 존재하는 것 같은데, 발표를 보아하니 그럼에도 split stack보다 퍼포먼스가 좋았으니 문제 삼지 않는 것 같다.