RANLP 2015
구현해야 하는데 시간이 없으니 일단 모델만 정리한다.
Model
저자는 Averaged Perceptron, HMM, CRFs, Bi-LSTMs+CRF, encoder-decoder model 실험했다.
잘 들어맞았던 건 character-based RNN with Bi-LSTM+CRF, 여기서 두 개의 character-based LSTM vector는 pre-trained word embedding과 concatenate한 것.
그 이후 이 embedding이 1개의 word를 가르킨다하고 word-level Bi-LSTM + CRF layer를 사용한다.
S2S(Syllable to Stress)
W2SP(Word to Stress Pattern)
pre-trained word embedding은 improvement를 살짝만 가져다 줌.
syllable이 space로 나뉘어 있으면 word structure를 잃으므로 WB(word boundary marker)를 만들어 놓고 실험한다.
Results
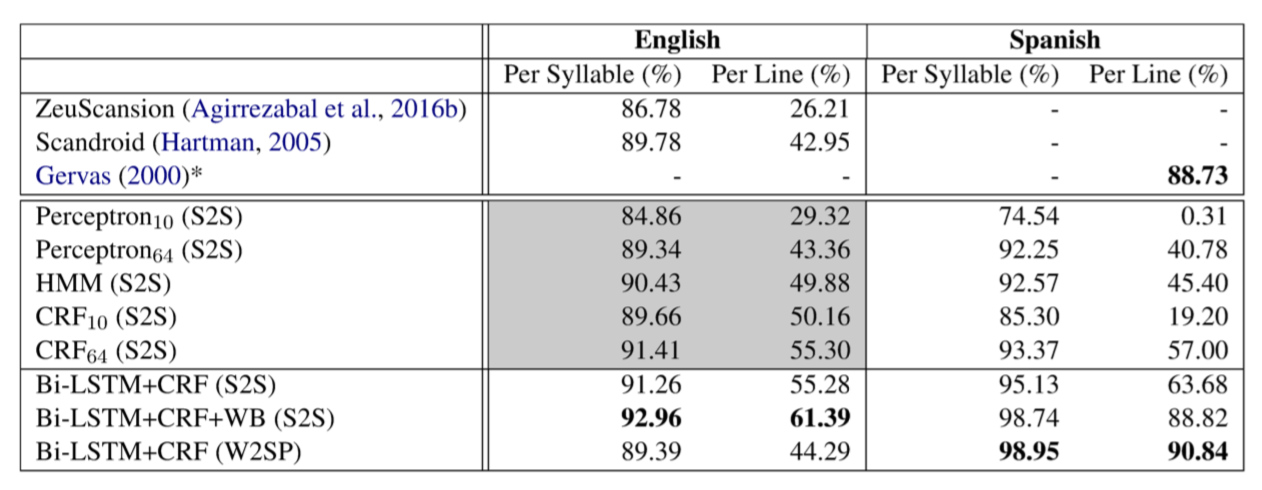
4B4V dataset에서는 Bi-LSTM+CRF+WB (S2S)가 제일 잘 나옴.