인용 수 20,000 이상의 ‘그 LDA’
베타 분포
베타 분포(Beta distribution)는 \(\alpha\), \(\beta\) 두 매개 변수에 대해 \([0, 1]\) 구간의 값을 가집니다.
좀 더 보시면 알겠지만 베타 분포는 \(K=2\)인 디리클레 분포입니다.
\[\text{Beta}(x; \alpha, \beta), \;\; 0 \leq x \leq 1\]베타 분포의 확률 밀도 함수는 다음과 같습니다.
\[\begin{align} \text{Beta}(x; \alpha, \beta) & = \frac{\Gamma(\alpha + \beta)}{\Gamma(\alpha)\Gamma(\beta)}\, x^{\alpha - 1}(1 - x)^{\beta - 1} \end{align}\]이 식의 감마 함수 \(\Gamma\)는 다음과 같이 정의된 특수 함수입니다.
\[\Gamma(\alpha) = \int_0^\infty x^{\alpha - 1} e^{-x}\, dx\]디리클레 분포
디리클레 분포(Dirichlet distribution)는 베타 분포의 확장판으로, 0과 1사이의 사이의 값을 가지는 다변수(multivariate) 확률 변수의 베이지안 모형에 사용됩니다.
변수가 \(K\)개일 경우, 각 변수가 확률을 나타내므로 \(\sum_{i=1}^{K} x_i = 1\) 를 만족해야 합니다.
디리클레 분포의 확률 밀도 함수는 다음과 같습니다.
\[\text{Dir}(x_1, x_2, \cdots, x_K; \alpha_1, \alpha_2, \cdots, \alpha_K) = \frac{1}{\mathrm{B}(\alpha_1, \alpha_2, \cdots, \alpha_K)} \prod_{i=1}^K x_i^{\alpha_i - 1}\]이 식에서의 베타 함수 \(\mathrm{B}\)는 다음과 같습니다.
\[\mathrm{B}(\alpha_1, \alpha_2, \cdots, \alpha_K) = \frac{\prod_{i=1}^K \Gamma(\alpha_i)} {\Gamma\bigl(\sum_{i=1}^K \alpha_i\bigr)}\]LDA
Latent Dirichlet Allocation (LDA, 잠재 디리클레 할당)
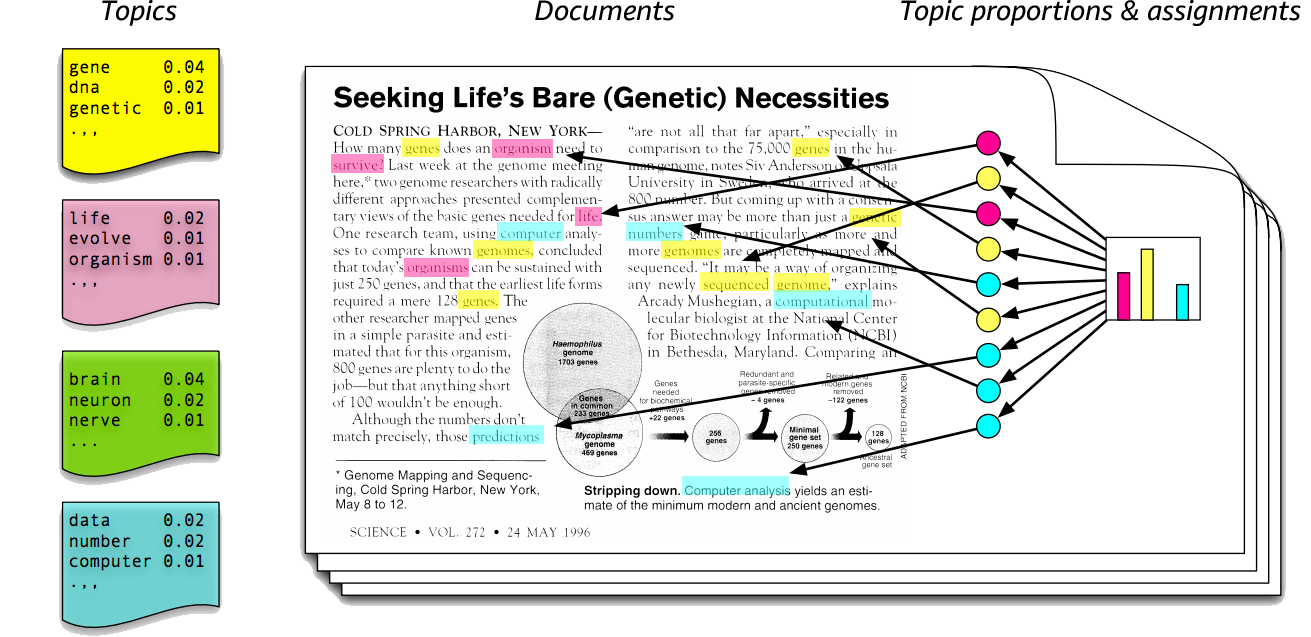
LDA는 Topic Modeling의 한 기법으로, 토픽별 단어의 분포와 문서별 토픽의 분포를 모두 추정해 냅니다.
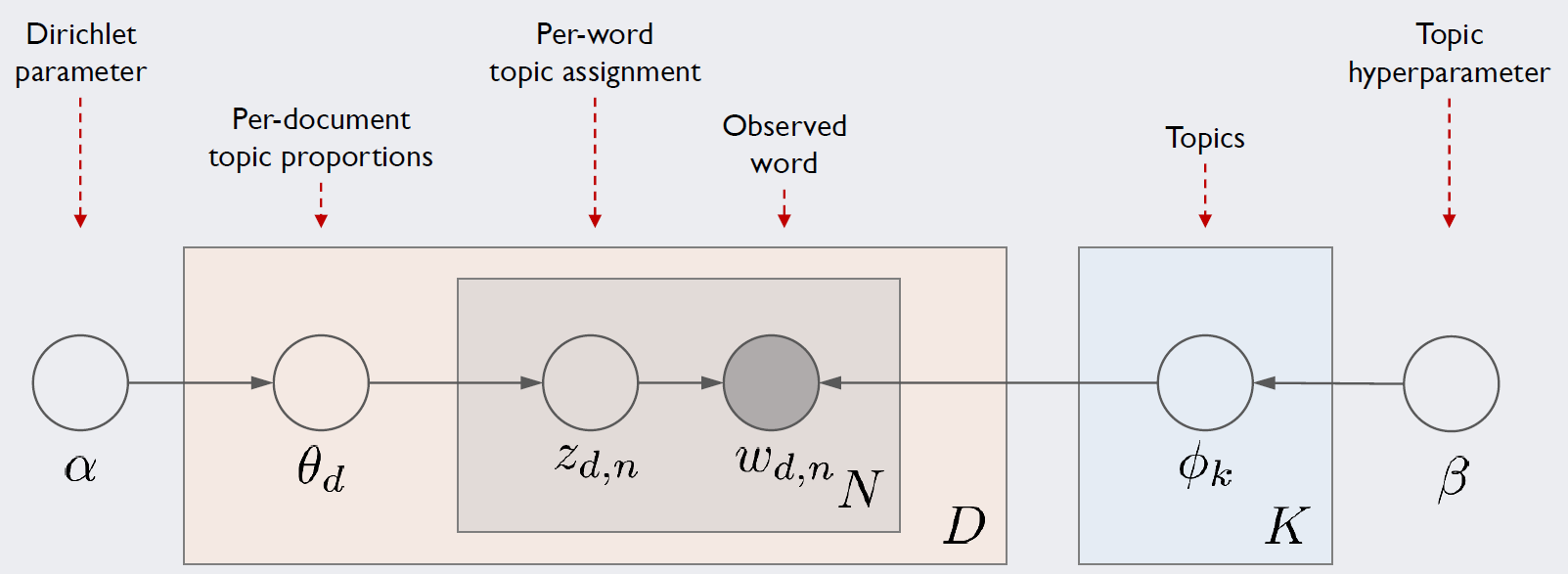
전체적으로 위와 같은 구조를 가집니다.
| 표기 | 값 |
|---|---|
| \(D\) | 문서 총 갯수 |
| \(K\) | 토픽의 총 갯수 |
| \(N\) | \(d\)번째 문서의 총 단어 갯수 |
| \(\Theta\) | 문서당 토픽 분포, \(\Theta_d\) ~ \(Dir(\alpha)\) for \(d \in \{1,2,...,D\}\) |
| \(\Phi\) | 토픽당 단어 분포, \(\Phi_k\) ~ \(Dir(\beta)\) for \(k \in \{1,2,...,K\}\) |
| \(z_{d,n}\) | 해당 단어의 토픽 분포, \(z_{d,n}\) ~ \(Multi(\Theta_d)\) |
| \(w_{d,n}\) | \(d\)번째 문서의 \(n\)번째 단어, \(w_{d,n}\) ~ \(Multi(\Phi_{z_{d,n}, n})\) |
하이퍼파라미터인 \(\alpha, \beta\)와 관찰 가능한 유일한 변수인 \(w_{d,n}\)을 이용하여 나머지 변수들을 모두 추정해야 합니다.
\(\alpha\)은 대게 0.1, \(\beta\)는 대게 0.001로 잡습니다.
LDA의 과정을 먼저 간략하게 설명하자면,
- 어떤 문서에 대해 파라미터 \(\Theta\)가 있고,
- 앞에서부터 단어를 하나씩 채울 때마다 \(\Theta\)로부터 하나의 토픽를 선택하고,
- 다시 그 토픽으로부터 단어를 선택하고 다시 앞에서부터 반복하는 방식으로 문서 생성 과정을 모델링하는 것입니다.
결국, 단어를 차례차례 관측하며 단어의 토픽 분포 \(z_{d,n}\)를 갱신하고 그 때마다 \(\Theta, \Phi\)의 디리클레 분포를 갱신하는 과정을 거치는 것입니다.
여기서 디리클레 분포의 이점이 나타납니다.
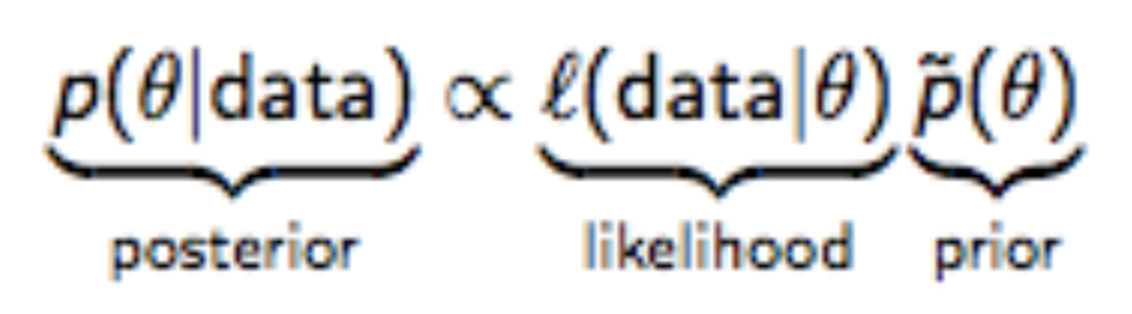
간략히 보자면 우리는 위와 같은 식을 반복하여 사용합니다. likelihood가 다항 분포를 따르는 상황에, Posterior를 최대로 하는 Prior를 구해 거듭 갱신시켜야 하는데 이 과정에서 Prior와 Posterior가 동일한 분포를 따르면 작업이 쉬워집니다. 그때 Prior와 Posterior의 분포를 Likelihood의 Conjugate Prior라고 부릅니다.
다항 분포의 Conjugate Prior가 바로 디리클레 분포입니다.
이제 실제로 \(p({z}|{w})\)를 최대로 하는 \(z\)를 찾는 과정 중 하나로 깁스 샘플링을 사용합니다. (다른 방법으로는 Variational Inference도 있습니다.)
깁스 샘플링
깁스 샘플링(Gibbs Sampling)
과정
LDA에 깁스 샘플링을 적용하여 우리가 구할 수 있는 값은
\[p({ z }_{ i }=j|{ z }_{ -i },w)\]가 됩니다.
\(z_{-i}\)는 \(i\)번째 단어의 토픽 정보를 제외한 모든 단어의 토픽 정보를 가리킵니다.
식 전체는 \(w\)와 \(z_{−i}\)가 주어졌을 때 문서의 \(i\)번째 단어의 토픽이 \(j\)일 확률을 뜻합니다.
- 초기에 모든 단어에 특정 토픽을 할당합니다.
- 첫 번째 문서 첫 번째 단어 \(z_{0,0}\)의 토픽 정보를 지웁니다.
- 해당 단어를 제외하고 토픽이 할당된 \(z_{-i}\)와 위 전체 식을 이용하여 \(z_{0,0}\)에 가장 적합한 토픽을 찾아 새로 할당합니다.
- 현재 문서에서 차례대로 다음 단어, 이후 다음 문서, … 이런 식으로 반복하며 2, 3 과정을 반복합니다.
- 충분히 반복하다 보면 수렴하게 됩니다.
의미
거인들이 행한 수식 정리를 거치면 다음과 같은 식을 얻게 됩니다.
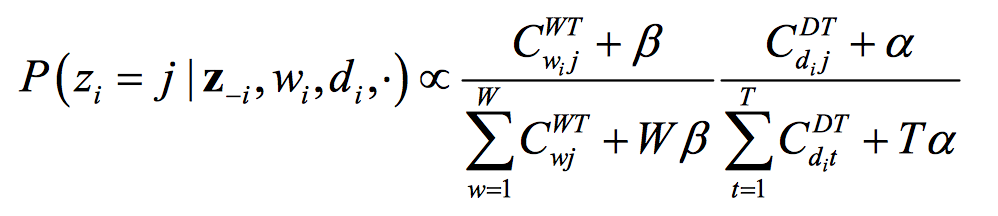
위 식은 \(d\)번째 문서의 \(i\)번째 단어 \(w\)의 토픽이 \(j\)일 확률은 다음의 두 가지에 영향을 받는다는 것을 뜻합니다.
- 토픽 \(j\)에 할당된 전체 단어 중에서 해당 단어의 점유율이 높을수록 \(j\)일 확률이 크다.
- \(i\)가 속한 문서 내 다른 단어가 토픽 \(j\)에 많이 할당되었을수록 \(j\)일 확률이 크다.
나머지
위 식 이후로도 유도를 더 해야하는 과정도 있습니다만, 여기서 더 자세하게 설명하기 보다는 연구의 경우 최신 논문에서 발전시키거나, 코딩이 필요할 경우 이미 있는 코드와 그 도큐먼트로 분석하는 것이 좋을거라 생각합니다.
참고 사이트
- http://www.4four.us/article/2014/10/lda-parameter-estimation
- https://bab2min.tistory.com/569?category=673750
- https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/06/01/LDA/